es的DSL语句
DSL(Domain Specific Language,领域特定语言)是Elasticsearch中用于构建查询和操作的语言,它提供了一套灵活的JSON格式来表达复杂的查询、过滤、聚合等操作。Elasticsearch的DSL主要用于查询数据、聚合分析、以及执行其他搜索相关的任务。
事前数据准备
PUT http://10.0.0.101:9200/oldboyedu-linux85-shopping
{
"mappings": {
"properties": {
"item": {
"type": "text"
},
"title": {
"type": "text"
},
"price": {
"type": "double"
},
"type": {
"type": "keyword"
},
"group": {
"type": "long"
},
"auther": {
"type": "text"
},
"birthday": {
"type": "date",
"format": "yyyy-MM-dd"
},
"province": {
"type": "keyword"
},
"city": {
"type": "keyword"
},
"remote_ip": {
"type": "ip"
}
}
}
}
导入数据
。。。。。
搜索匹配
全文检索-match查询
GET 10.0.0.101:9200/oldboyedu-linux85-shopping/_search
{
"query":{
"match":{
"auther":"彭斌"
}
}
}
## 含有文字既可以出现
精确匹配-match_phrase查询
### 精准匹配
{
"query":{
"match_phrase":{
"auther":"张宇杰"
}
}
}
精准匹配多个值-terms
{
"query": {
"terms": {
"price": [
9.9,
19.9
]
}
}
}
全量检索-match_all
### 查询所有索引下的数据
{
"query": {
"match_all": {}
}
}
分页查询(size)
(1)每页显示3条数据,查询第四页
{
"query":{
"match_phrase":{
"auther":"张宇杰"
}
},
"size": 3,
"from":9
}
相关参数说明:
size:
指定每页显示多少条数据,默认值为10.
from:
指定跳过数据偏移量的大小,默认值为0,即默认看第一页。
查询指定页码的from值 = "(页码 - 1) * 每页数据大小(size)"
温馨提示:
生产环境中,不建议深度分页,百度的页码数量控制在76页左右。计算量太大
查看指定字段的(_source)
{
"query":{
"match_phrase":{
"auther":"丘鸿彬"
}
},
"_source":["title","auther","price"]
}
查看 精准匹配 丘鸿彬 下的 "title","auther","price"
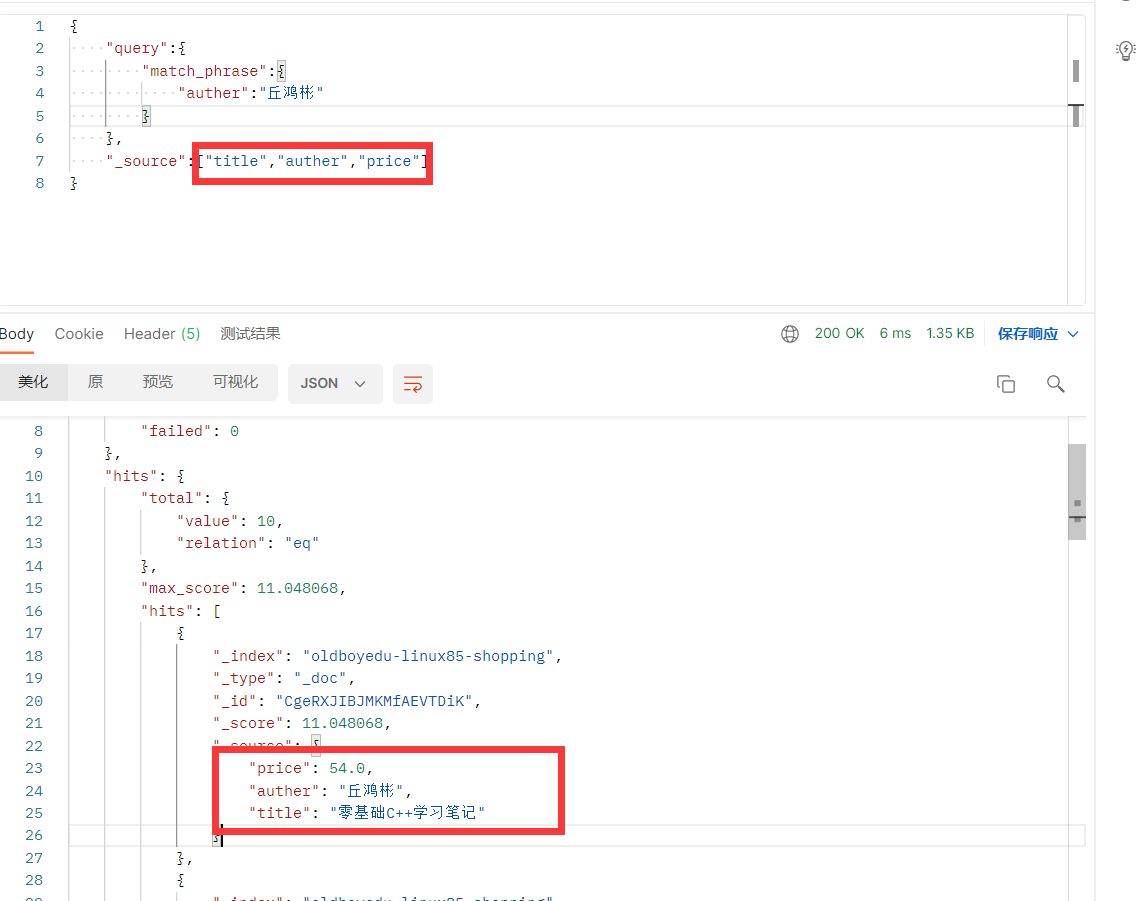
查询存在某个字段的文档-(exists)
{
"query": {
"exists" : {
"field": "hobby"
}
}
}
语法高亮
{
"query": {
"match_phrase": {
"title": "孙子兵法"
}
},
"highlight": {
"pre_tags": [
"<span style='color:red;'>"
],
"post_tags": [
"</span>"
],
"fields": {
"title": {}
}
}
}
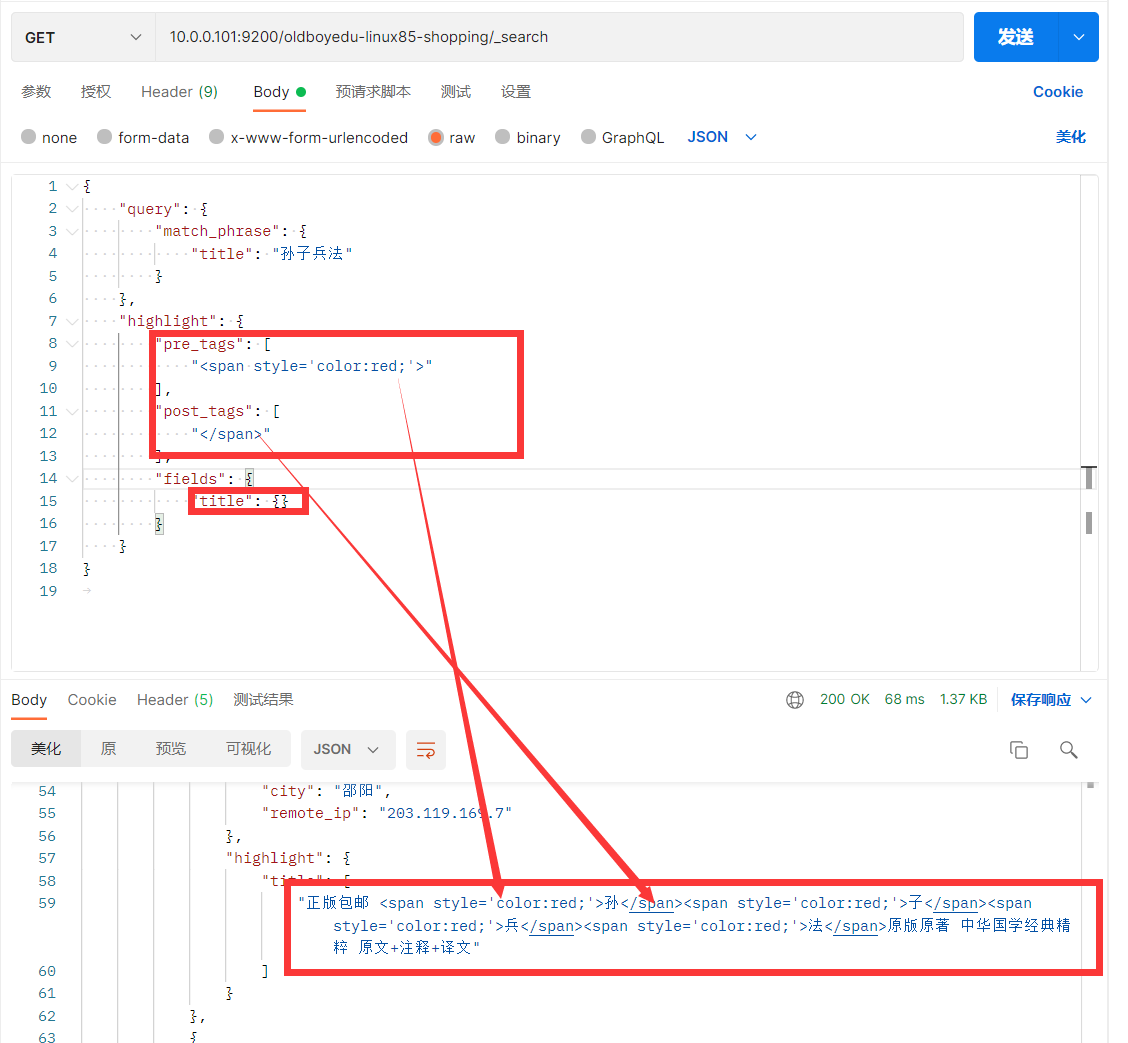
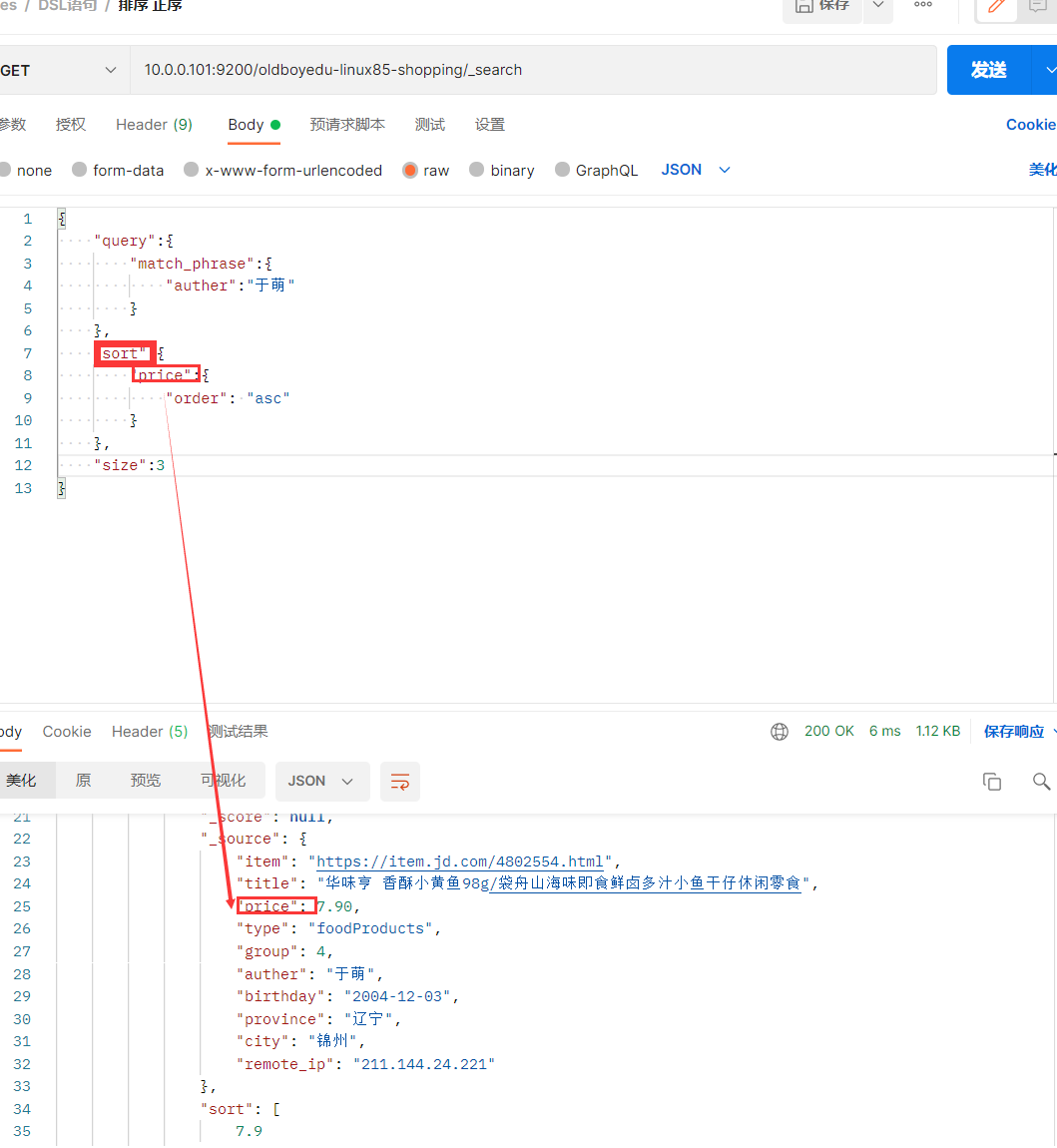
排序
相关字段说明:
sort:
基于指定的字段进行排序。此处为指定的是"price"
order:
指定排序的规则,分为"asc"(升序)和"desc"(降序)。
### 正序
{
"query":{
"match_phrase":{
"auther":"于萌"
}
},
"sort":{
"price":{
"order": "asc"
}
},
"size":1
}
### 倒叙
{
"query":{
"match_phrase":{
"auther":"于萌"
}
},
"sort":{
"price":{
"order": "desc"
}
},
"size":3
}
多条件查询(bool)
# 查看作者是于萌且商品价格为24.90 同时满足
## must
{
"query": {
"bool": {
"must": [
{ "match_phrase": {"auther": "于萌"} },
{ "match": { "price": 24.90}
}
]
}
}
}
### 查看作者是于萌或者是高超的商品并降序排序
## should
{
"query": {
"bool": {
"should": [
{
"match_phrase": {
"auther": "于萌"
}
},
{
"match_phrase": {
"auther": "高超"
}
}
]
}
},
"sort":{
"price":{
"order": "desc"
}
}
}
#### 查看作者是于萌或者是高超且商品价格为168或者198
{
"query": {
"bool": {
"should": [
{
"match_phrase": {
"auther": "于萌"
}
},
{
"match_phrase": {
"auther": "高超"
}
},
{
"match": {
"price": 168.00
}
},
{
"match": {
"price": 198.00
}
}
],
"minimum_should_match": "60%"
}
}
}
#### 查看作者不是于萌或者是高超且商品价格为168或者198的商品
{
"query": {
"bool": {
"must_not": [
{
"match_phrase": {
"auther": "于萌"
}
},
{
"match_phrase": {
"auther": "高超"
}
}
],
"should": [
{
"match": {
"price": 168.00
}
},
{
"match": {
"price": 198.00
}
}
],
"minimum_should_match": 1
}
}
}
过滤查询 (must)
-查询3组成员产品价格3599到10500的商品的最便宜的3个
{
"query": {
"bool": {
"must": [
{
"match": {
"group": 3
}
}
],
"filter": {
"range": {
"price": {
"gte": 3599,
"lte": 10500
}
}
}
}
},
"sort": {
"price": {
"order": "asc"
}
},
"size": 3
}
详解bool查询
bool查询:结合多个查询条件,允许使用must、should、must_not等子句来构建复杂的布尔逻辑查询。
must:类似于逻辑上的AND,文档必须匹配must中的所有查询条件。
filter:也类似于AND,但是不同于must,filter不会影响文档的相关性评分。它常用于高效地筛选数据,性能上比must更好,因为不计算相关性。
should:类似于逻辑上的OR,文档匹配should中的任意一个条件就算匹配成功。如果bool查询中只有should子句,它会像OR一样操作。如果同时有must或filter子句,那么should子句的匹配会增加文档的相关性得分。
must_not:类似于逻辑上的NOT,文档必须不匹配must_not中的查询条件。
{
"query": {
"bool": {
"must": [
{ "match": { "title": "Elasticsearch" } },
{ "range": { "publish_date": { "gte": "2022-01-01" } } }
],
"filter": [
{ "term": { "status": "published" } }
],
"should": [
{ "match": { "author": "John" } },
{ "match": { "author": "Doe" } }
],
"must_not": [
{ "term": { "is_deleted": true } }
]
}
}
}
must:文档必须同时满足title包含"Elasticsearch"和publish_date在2022年1月1日及以后的条件。
filter:文档的status字段必须为published,但它不会影响文档的得分计算(相关性评分)。
should:如果文档的author字段包含"John"或"Doe",文档的相关性得分会增加,但不是强制条件。
must_not:文档的is_deleted字段不能为true。
1. must
must子句包含的条件必须全部满足,类似于SQL中的AND。
{
"query": {
"bool": {
"must": [
{ "match": { "title": "Elasticsearch" } },
{ "term": { "category": "search" } }
]
}
}
}
此查询要求文档的title字段中必须包含"Elasticsearch",且category字段必须为"search"。
2. filter
filter子句与must相似,但它不会参与相关性评分的计算,因此在执行查询时性能更好。通常用来对数据进行高效的过滤。
{
"query": {
"bool": {
"filter": [
{ "term": { "status": "published" } },
{ "range": { "publish_date": { "gte": "2022-01-01" } } }
]
}
}
}
此查询只会返回status为published,并且publish_date在2022年1月1日及之后的文档。
3. should
should子句用于提高文档的相关性得分。多个should条件相当于OR逻辑,文档只需要匹配其中的一个条件即可。通常,should子句的作用是增加文档的匹配概率。
{
"query": {
"bool": {
"should": [
{ "match": { "tags": "search" } },
{ "match": { "tags": "elasticsearch" } }
]
}
}
}
此查询返回文档只需要匹配tags字段中的一个条件即可,即tags字段包含search或elasticsearch之一。
强制至少满足一个should条件: 当你希望should中的某些条件必须满足时,可以通过设置minimum_should_match参数实现。例如,下面的查询要求至少匹配一个should条件:
{
"query": {
"bool": {
"should": [
{ "match": { "tags": "search" } },
{ "match": { "tags": "elasticsearch" } }
],
"minimum_should_match": 1
}
}
}
4. must_not
must_not子句用于排除文档,类似于NOT逻辑。文档不能匹配其中的任何条件。
{
"query": {
"bool": {
"must_not": [
{ "term": { "is_deleted": true } }
]
}
}
}
此查询将排除所有is_deleted字段为true的文档。
详解权重
在Elasticsearch中,权重(boost)是用于调整查询相关性得分的重要工具。通过设置权重,可以增加或降低某些字段、查询条件在最终结果中的影响,使得某些条件更加重要或不太重要。这种调整可以帮助你优化搜索结果的排序,更符合业务需求或用户期望。
权重的应用场景
- 提升特定字段的重要性:例如,在搜索文档时,你可能希望标题字段的匹配比内容字段的匹配更重要。
- 平衡多条件查询:如果一个查询由多个子查询组成,可以通过调整不同子查询的权重,确保特定的条件比其他条件更关键。
- 控制相关性得分:Elasticsearch通过TF/IDF算法计算文档的相关性得分,权重可以直接影响得分的计算结果,从而影响文档在结果中的排序。
权重的设置方式
权重可以在以下几个地方设置:
- 字段级权重(Field Boosting):在查询中为某些字段分配更高的权重,使它们在搜索结果中影响更大。
- 查询级权重(Query Boosting):为不同的查询条件分配不同的权重,提升某些条件的重要性。
- 函数评分查询(Function Score Query):更灵活地基于自定义函数调整相关性得分。
1. 字段级权重
你可以在查询中为某个字段设置权重,使得这个字段的匹配结果更具权重。例如,如果你希望title字段的匹配比description字段更重要,可以使用boost来提升权重:
{
"query": {
"multi_match": {
"query": "Elasticsearch",
"fields": [
"title^2", // title字段的权重为2
"description"
]
}
}
}
解释:
fields: 指定查询的字段。title^2 表示title字段的权重为2,而description字段的权重为默认的1。这样,当文档中的title字段匹配到关键词"Elasticsearch"时,得分会是匹配description字段的两倍。
2. 查询级权重
boost还可以应用于整个查询,来提升某个查询子句的权重。下面是一个使用bool查询的例子,其中为不同的查询子句设置了权重:
{
"query": {
"bool": {
"should": [
{
"match": {
"title": {
"query": "Elasticsearch",
"boost": 3 // 提高title字段匹配的权重
}
}
},
{
"match": {
"content": {
"query": "Elasticsearch",
"boost": 1 // content字段的默认权重
}
}
}
]
}
}
}
解释:
title字段的权重被设置为3,表示它在相关性计算中的影响力比content字段大。匹配title字段的文档将排在更靠前的位置,而匹配content字段的文档则会排在次要位置。
3. 函数评分查询(Function Score Query)
function_score查询可以用更加灵活的方式调整文档的相关性得分。它允许你基于某些特定的函数对得分进行调整,比如基于文档字段值、随机数、距离等因素来修改得分。
{
"query": {
"function_score": {
"query": {
"match": {
"description": "Elasticsearch"
}
},
"boost": 1.5, // 给整个查询一个基础权重
"functions": [
{
"filter": { "term": { "category": "search" } }, // 如果匹配到某个条件
"weight": 2 // 增加额外权重
},
{
"field_value_factor": {
"field": "popularity", // 使用popularity字段的值影响得分
"factor": 1.2,
"modifier": "sqrt", // 使用平方根来调节影响
"missing": 1 // 如果字段不存在,使用默认值1
}
}
],
"boost_mode": "multiply" // 将查询得分和权重进行相乘
}
}
}
解释:
query: 基本查询部分,搜索description字段中包含Elasticsearch的文档。
boost: 给整个查询一个基础的权重,1.5倍。
functions: 包含多个函数,用于调整得分。比如,term查询如果匹配category字段为search,则增加2倍权重;或者根据popularity字段的值,使用平方根来影响得分。
boost_mode: 设置为multiply,表示最终得分是查询得分和权重的乘积。
示例
示例1:提升标题的匹配权重
在一个文档系统中,通常希望标题的匹配比正文重要,可以这样设置:
{
"query": {
"multi_match": {
"query": "Elasticsearch tutorial",
"fields": ["title^3", "content"]
}
}
}
在这个查询中,标题的权重为正文的3倍,如果文档的title字段包含"Elasticsearch tutorial",它会比仅在content字段中匹配的文档得分更高。
示例2:根据流行度字段调整结果排序
如果你在一个电子商务网站中存储了商品,并且想让受欢迎的商品排在更前面,可以使用function_score查询基于popularity字段调整排序:
{
"query": {
"function_score": {
"query": {
"match": { "description": "laptop" }
},
"field_value_factor": {
"field": "popularity",
"factor": 1.2,
"modifier": "log1p",
"missing": 1
}
}
}
}
这将会根据popularity字段的值调整文档的得分,更受欢迎的商品会有更高的相关性得分。