ElasticSearch 简介

Elasticsearch 是一个分布式、高扩展、高实时的搜索与数据分析引擎 。基于 Java 开发,并使用 Lucene 作为核心库,实现所有索引和搜索的功能;可以处理大规模日志数据,实现数据的实时全文搜索搜索、支持分布式可实现高可用、提供API接口;Elasticsearch 的实现原理主要分为以下几个步骤
①. — 用户将数据提交到 Elasticsearch 数据库中
②. — 通过分词控制器去将对应的语句分词,将其权重和分词结果一并存入数据
③. — 用户搜索数据时,**根据权重将结果排名,打分,再返回结果 **
Elasticsearch支持分布式,这意味着索引可以被分片,每个分片可以有 0 个或多个副本,每个节点托管一个或多个分片,并充当协调器将操作委托给正确的分片。再平衡和路由是自动完成的。“相关数据通常存储在同一个索引中,该索引由一个或多个主分片和零个或多个复制分片组成。一旦创建了索引,就不能更改主分片的数量。
Elasticsearch 是与名为 Logstash 的数据收集和日志解析引擎以及名为 Kibana 的分析和可视化平台一起开发的,这三个产品被设计成一个集成解决方案,称为 “Elastic Stack”(以前称为 “ELK stack”)。
数据模型对比
结构化数据
结构化数据也称作行数据,是由二维表结构来逻辑表达和实现的数据,严格地遵循数据格式与长度规范,主要通过关系型数据库进行存储和管理 。
结构化数据存储时,严格遵守固定数据格式与长度规范,使用 SQL (结构化查询语言)查询
非结构化数据
与结构化数据相对的是不适于由数据库二维表来表现的非结构化数据,包括所有格式的办公文档、XML、HTML、各类报表、图片和音频、视频信息等 。
非结构化数据存储时,没有固定的存储格式,一般使用顺序扫描、全文搜索
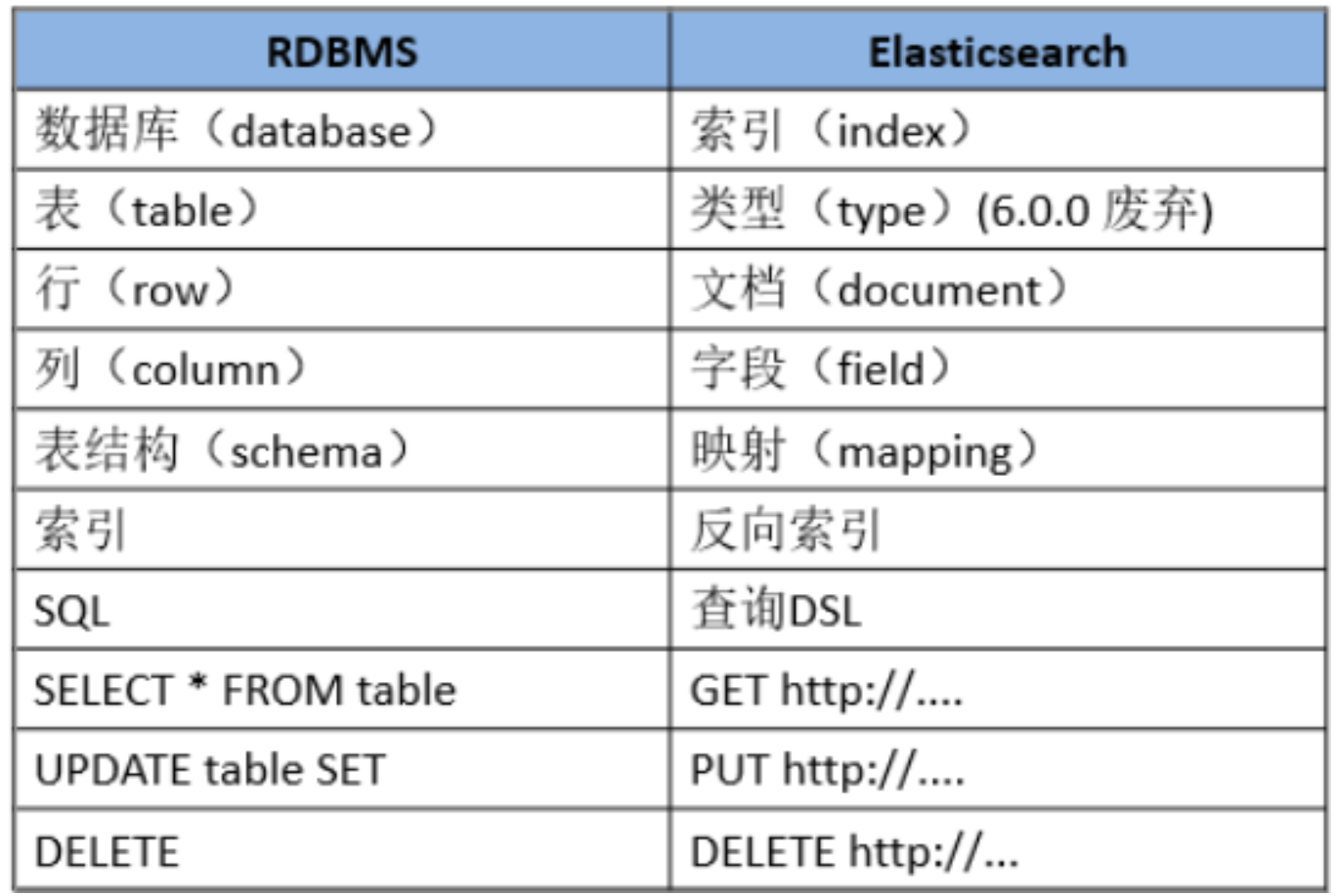
ElasticSearch 和 MySQL 结构对比
ElasticSearch 原理
①. — 存储数据时进行全文检索
②. — 全文检索后建立倒排索引
全文检索
将一个数据的内容转化拆分
①. — 分词
②. — 找到关键词
③. — 搜索索引
④. — 匹配,命中,计算命中率
⑤. — 根据命中率进行排序
倒排索引
Copydocument_1: Java 是世界上最好的语言
document_2: PHP 是世界上最好的语言
document_3: Python 是世界上最好的语言
| Term(分词后的词条) | Document_1 | Document_2 | Document_3 |
|---|---|---|---|
| Java | 命中 | ||
| 是 | 命中 | 命中 | 命中 |
| 世界上 | 命中 | 命中 | 命中 |
| 最好的 | 命中 | 命中 | 命中 |
| 语言 | 命中 | 命中 | 命中 |
| PHP | 命中 | ||
| Python | 命中 |
实际上一些停顿词(的、了、着、是 、标点符号)不会被记录到词条(Term)中
倒排索引术语
①. —— 词条(Term):索引最小的存储单位,拆分一组词之后,每一个字或者词
②. —— 词典(Term Dictionary):词条存储的地方,一般在内存中
③. —— 倒排表:记录多个词命中的次数和顺序
④. —— 倒排文件:存储倒排表的地方,一般在磁盘中
倒排索引介绍:https://www.cnblogs.com/ajianbeyourself/p/11280247.html