分词器
在Elasticsearch中,分词器(Analyzer)是用于将文本字段拆解成一系列独立的词项(terms)以便进行索引和搜索。分词器对于处理 text 类型的字段尤为重要,因为 text 类型字段会在索引过程中经过分词,生成可以被搜索的词项。分词器的作用是提高全文检索的准确性和效率。
分词器由三个主要组件组成:
- 字符过滤器(Character Filters):字符过滤器在文本进行分词之前应用,处理文本的预处理操作。它可以用来规范化或清理文本,如去掉HTML标签或转换特殊字符。
- 分词器(Tokenizer):分词器的任务是将输入的文本流拆解成独立的词项。每个词项代表文本中的一个最小单元,可以是一个词、一个子串或其他任何形式的符号。
- 词项过滤器(Token Filters):词项过滤器在分词后应用,用来进一步处理词项,如大小写转换、去除停用词(Stop Words)、词干提取等。
常见的分词器
常规分词器
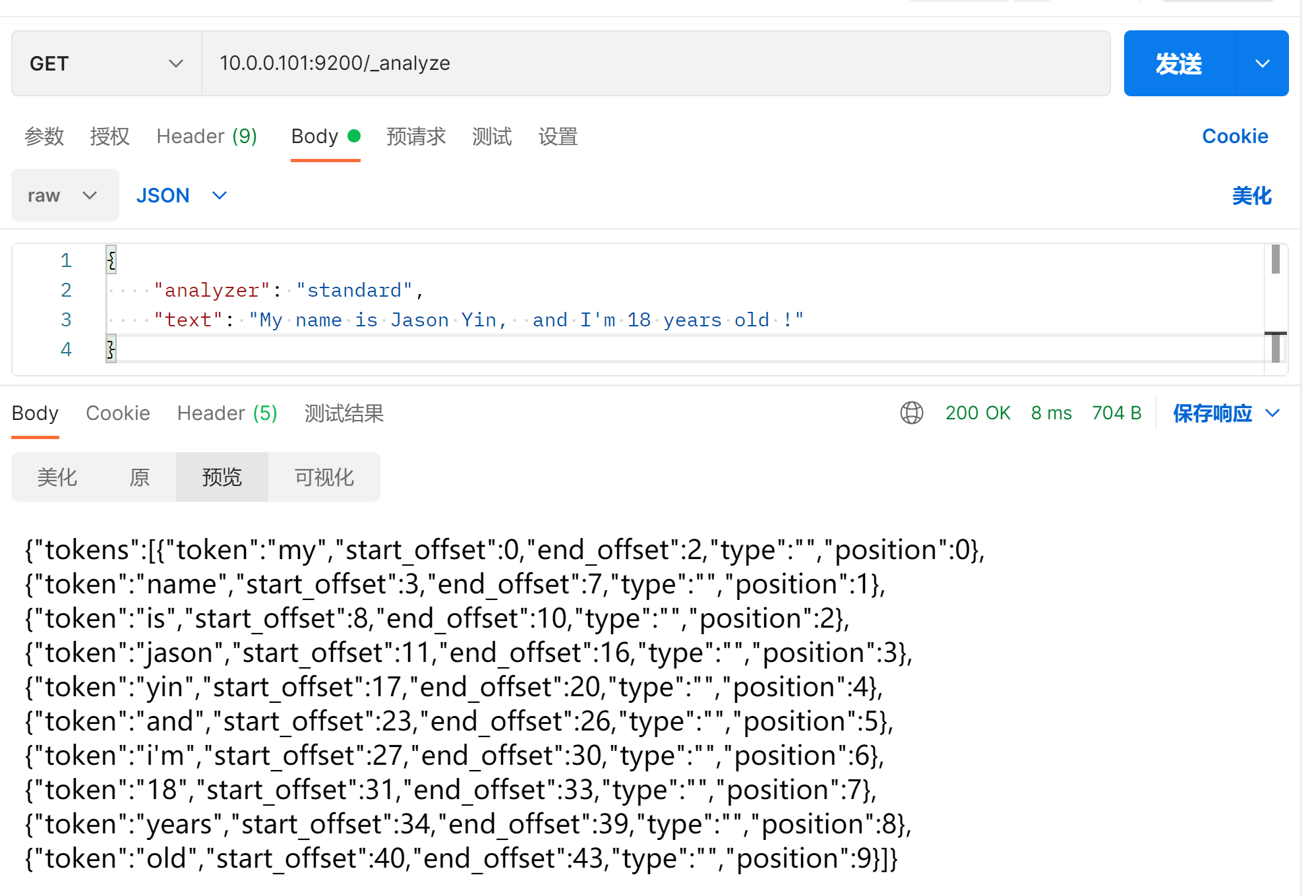
GET http://10.0.0.101:9200/_analyze
{
"analyzer": "standard",
"text": "My name is Jason Yin, and I'm 18 years old !"
}
它使用Unicode文本分割算法进行分词,处理复杂的语言结构,并去除标点符号、分隔符等。
温馨提示:
标准分词器模式使用空格和符号进行切割分词的。
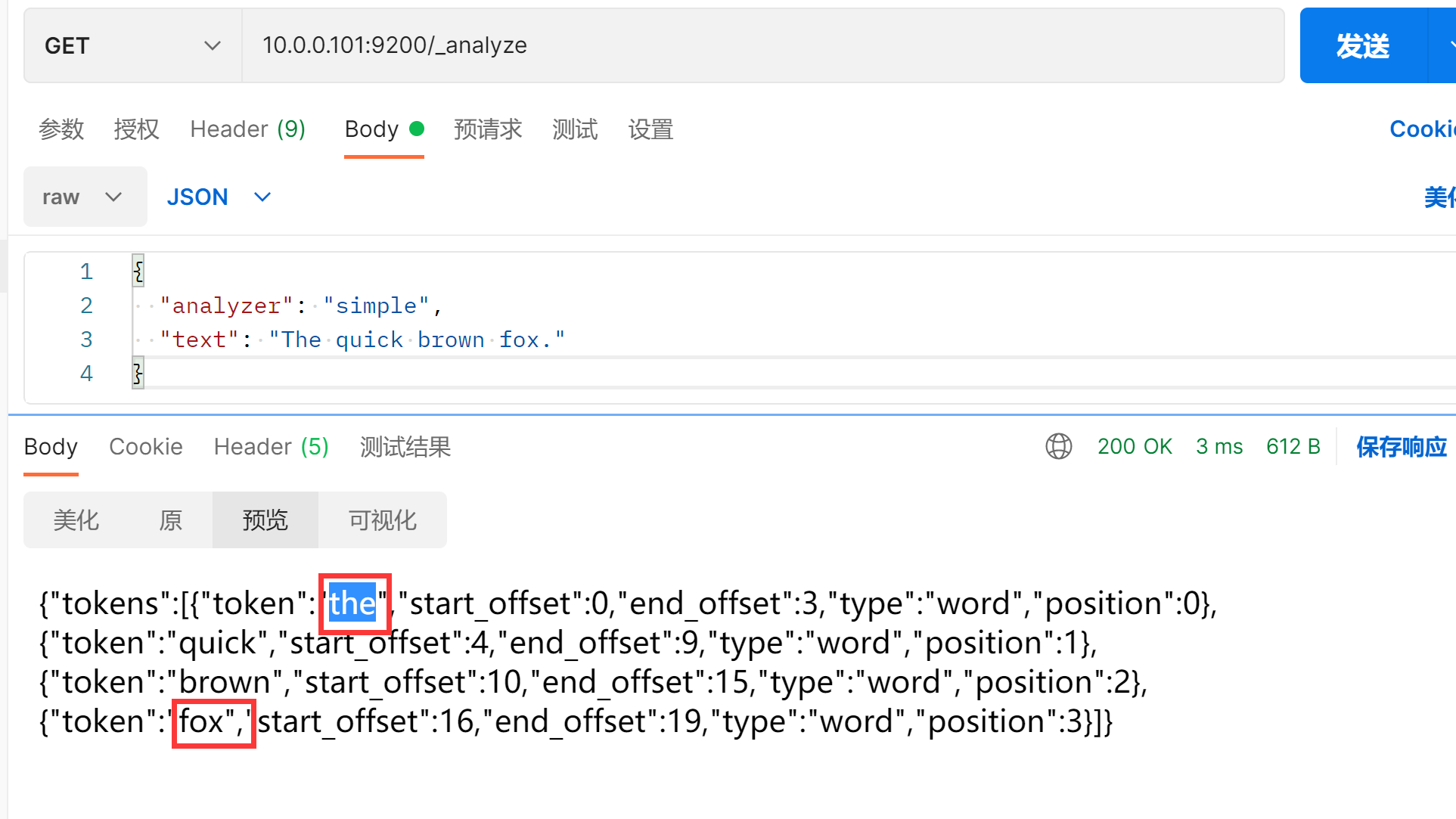
简易分词器
GET /_analyze
{
"analyzer": "simple",
"text": "The quick brown fox."
}
使用非字母字符将文本分割为词项,转换为小写,保留最简单的词项。
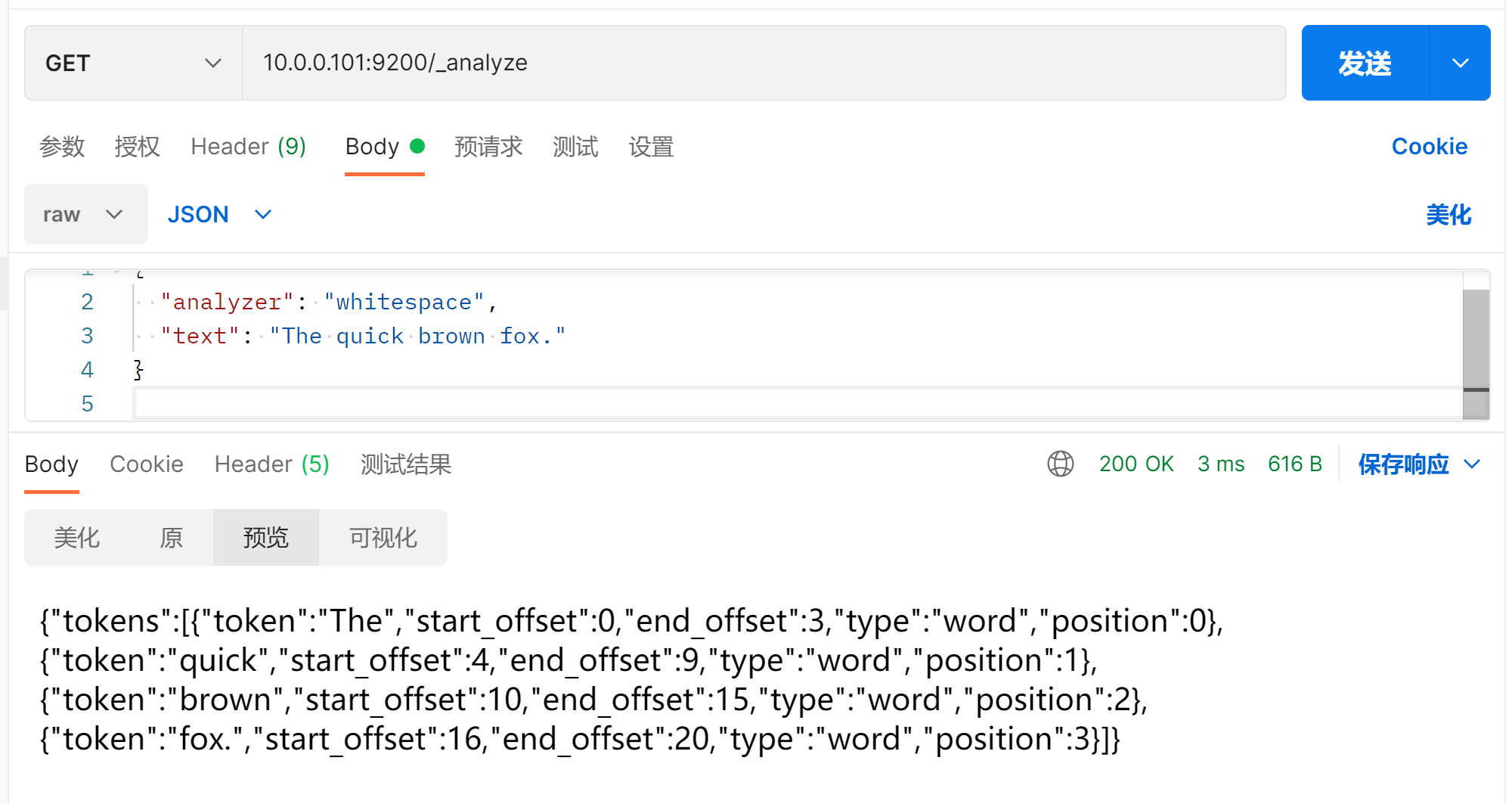
空格分词器
GET /_analyze
{
"analyzer": "whitespace",
"text": "The quick brown fox."
}
基于空格将文本分割成词项,不做其他处理。
对结构化文本或希望保留特殊符号的场景比较有用。
#### 以上的分词器对中文不友好
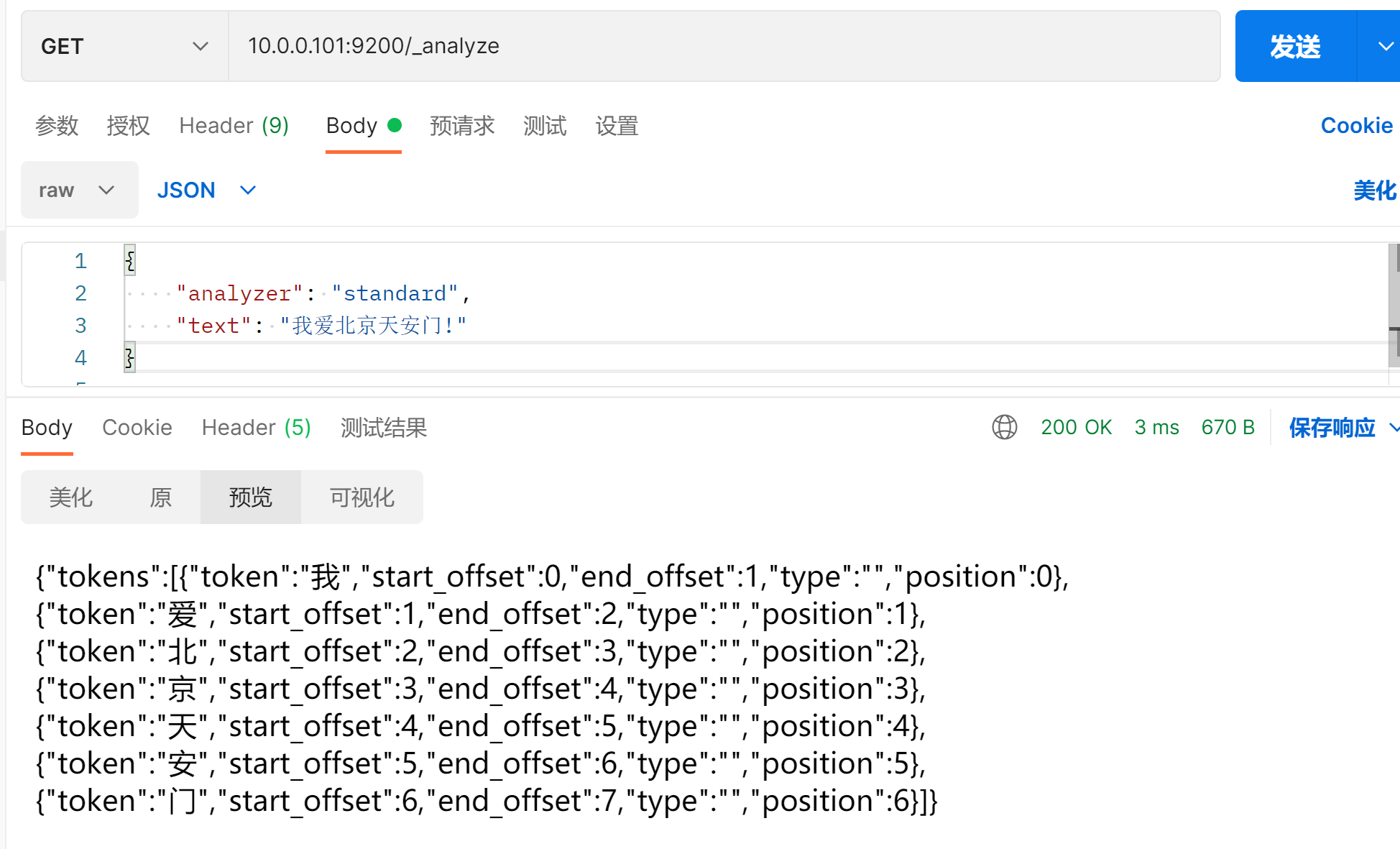
安装IK分词器
### 创建目录
mkdir /app/elasticsearch-7.17.5/plugins/ik
### 上传解压文件
unzip elasticsearch-analysis-ik-7.17.5.zip
rm -f elasticsearch-analysis-ik-7.17.5.zip
scp -r /app/elasticsearch-7.17.5/plugins/ik 10.0.0.102:/app/elasticsearch-7.17.5/plugins/
scp -r /app/elasticsearch-7.17.5/plugins/ik 10.0.0.103:/app/elasticsearch-7.17.5/plugins/
### 重启服务
systemctl restart es7
进行测试
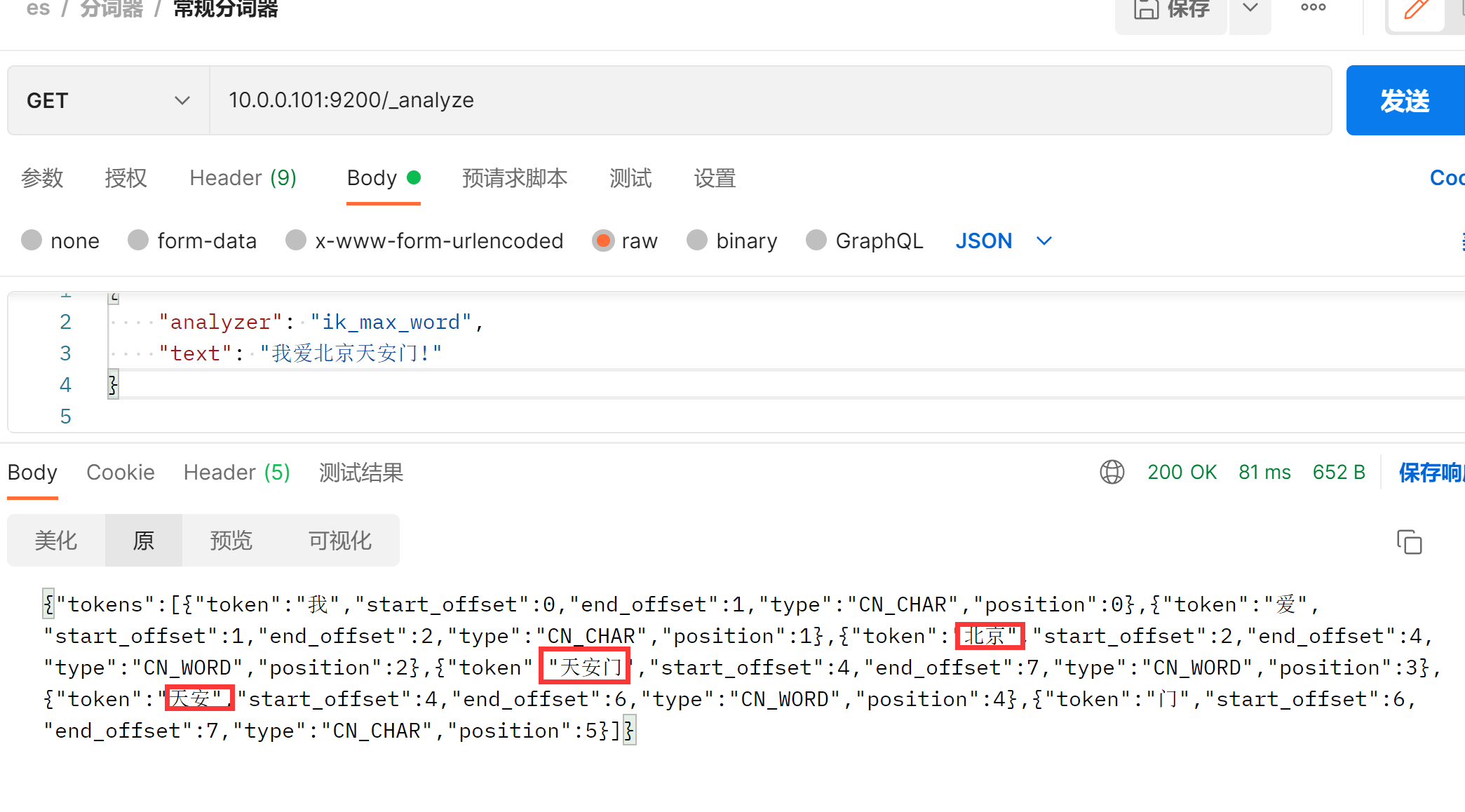
### 细粒度拆分
GET /_analyze
{
"analyzer": "ik_max_word",
"text": "我爱北京天安门!"
}
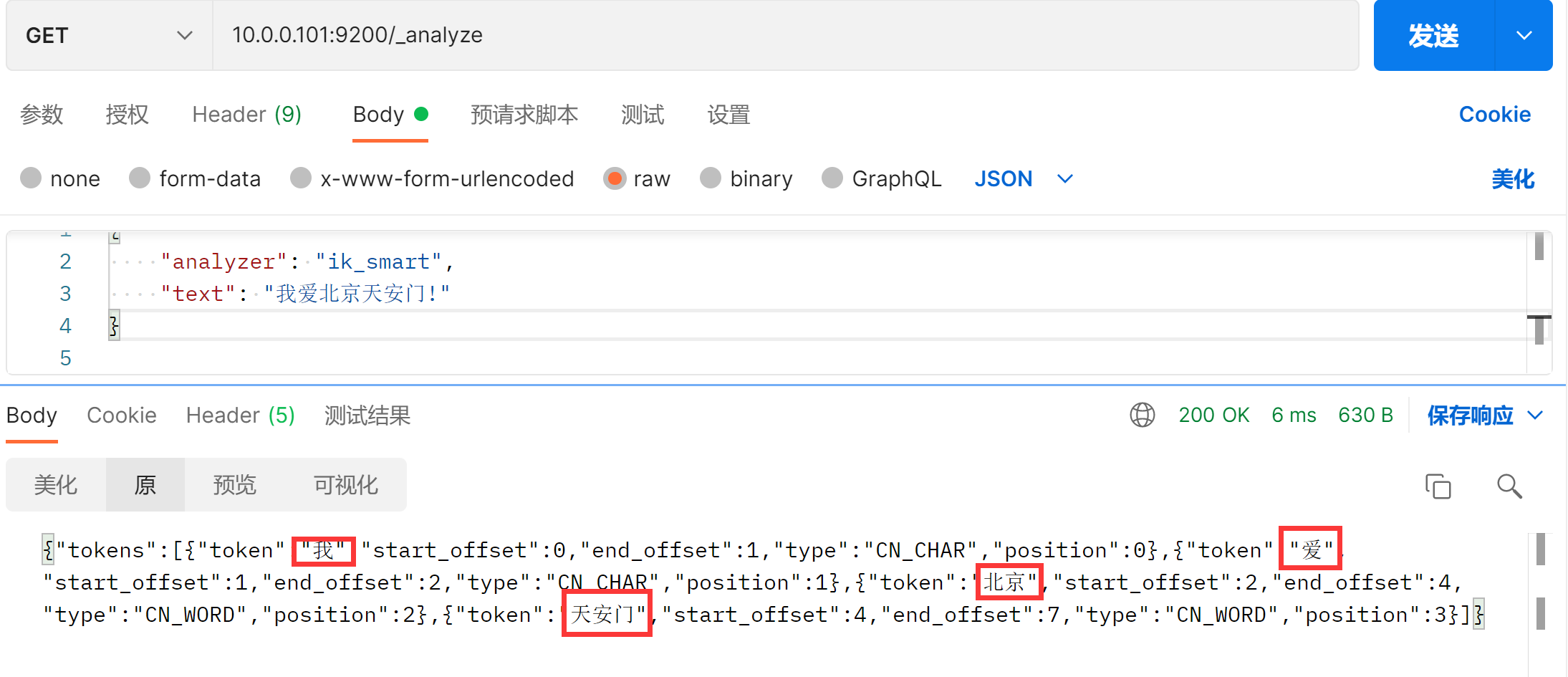
### 测试IK中文分词器-粗粒度拆分
{
"analyzer": "ik_smart",
"text": "我爱北京天安门!"
}
自定义ik字典
默认
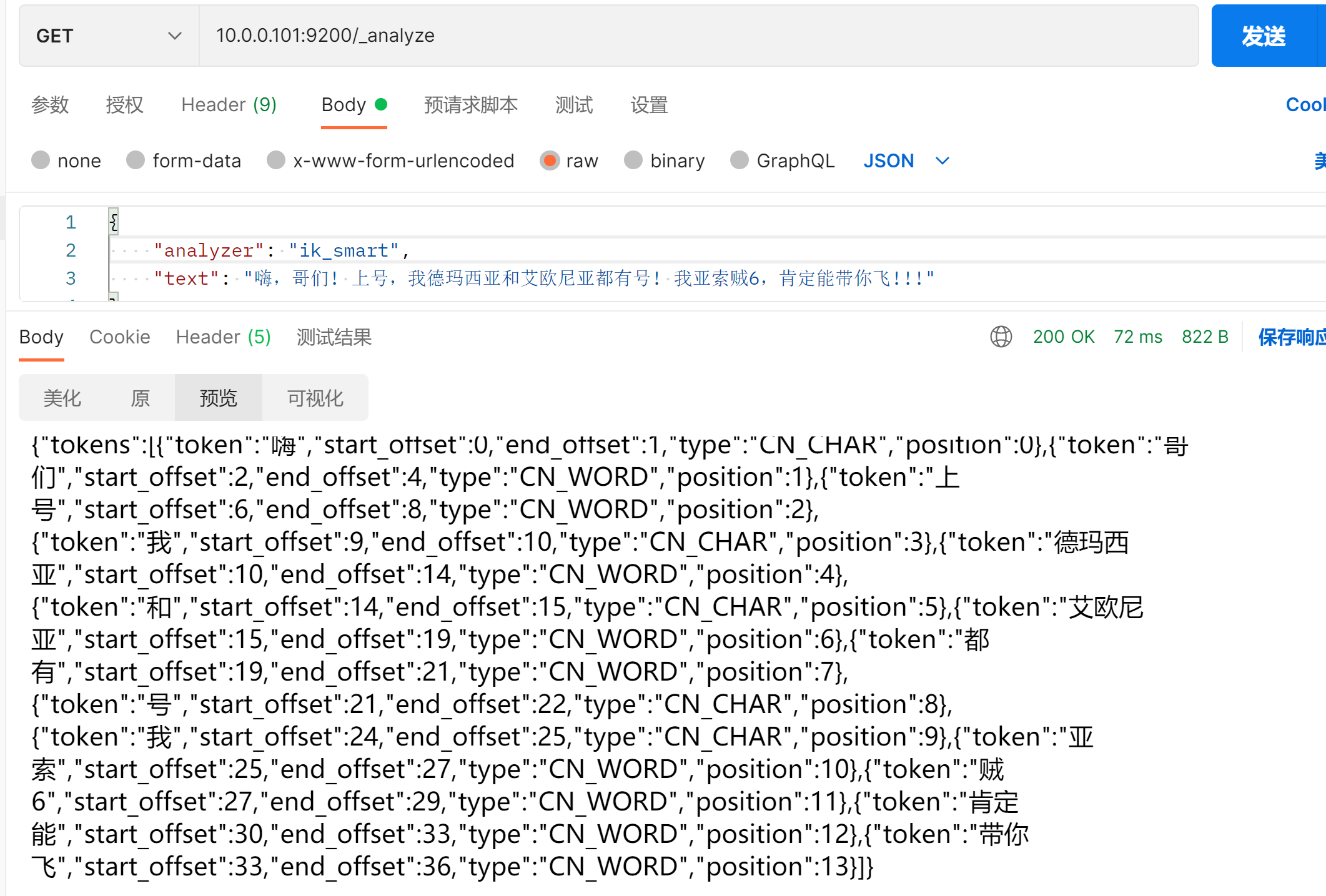
{
"analyzer": "ik_smart",
"text": "嗨,哥们! 上号,我德玛西亚和艾欧尼亚都有号! 我亚索贼6,肯定能带你飞!!!"
}
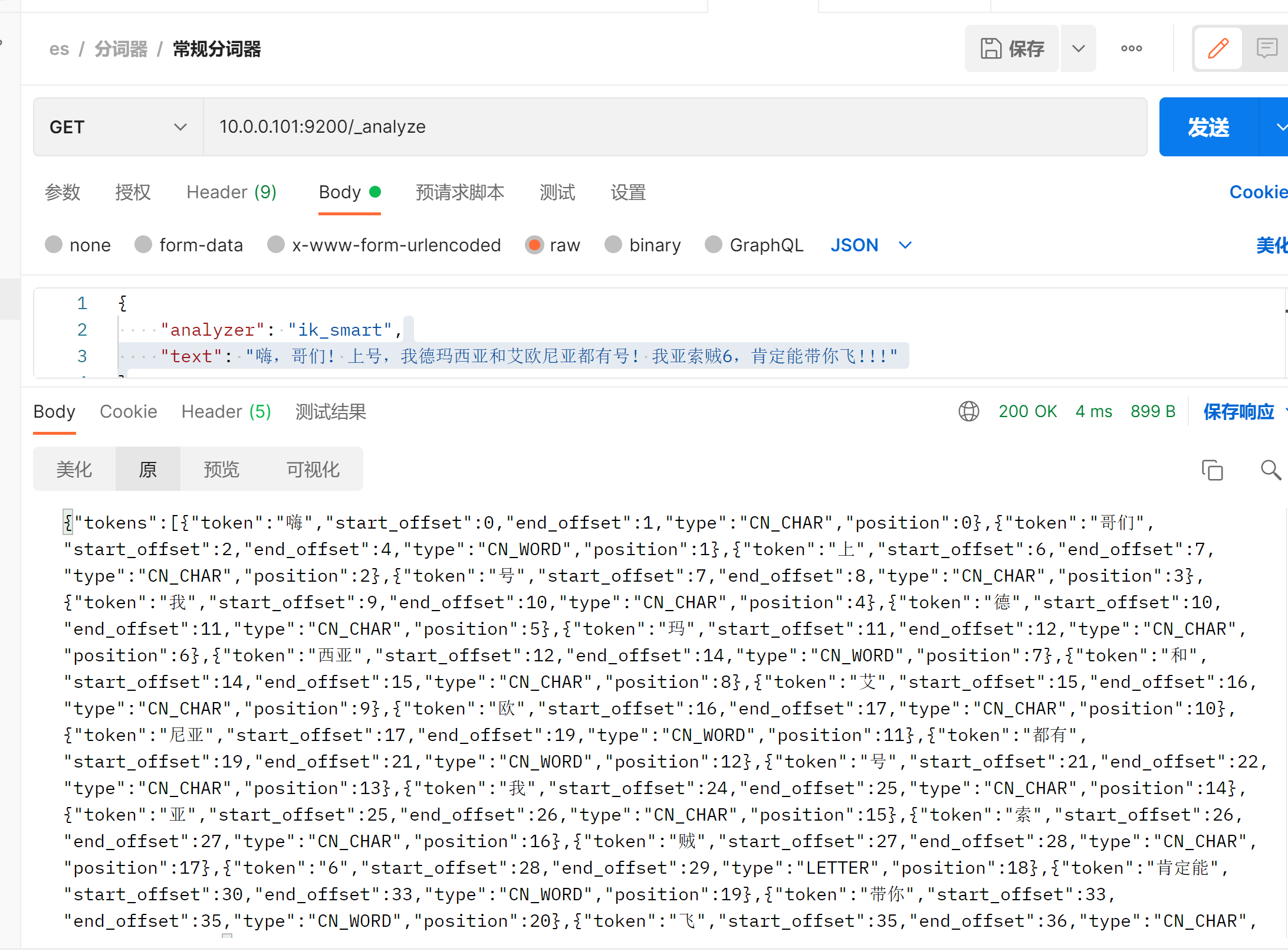
(1)进入到IK分词器的插件安装目录
cd /app/elasticsearch-7.17.5/plugins/ik/config
(2)自定义字典
cat > diy.dic <<'EOF'
德玛西亚
艾欧尼亚
亚索
上号
带你飞
贼6
EOF
(3)加载自定义字典
vim IKAnalyzer.cfg.xml
...
<entry key="ext_dict">diy.dic</entry>
(4)重启ES集群
systemctl restart es7