Prometheus 常用的函数
PromeQL查询结果类型
# PromQL的表达式中支持以下四种数据类型:
即时向量(Instant Vector):
特定或全部的时间序列集合上,具有相同时间戳的一组样本称为即时向量。
范围向量(Range Vector):
特定或全部的时间序列集合上,在指定的同一范围内的所有样本值。
标量(Scalar):
一个浮点型的数据值。
字符串(String):
支持使用单引号,双引号或反引号进行引用,但反引号中不会转移字符进行转义。
Prometheus常用的函数
- sum(): 对样本值求和
- avg(): 对样本值求平均值 这是进行指标数据分析的标准方法
- count(): 对分组内的时间序列进行数量统计
- stddev(): 对样本值求标准差 以帮组用户了解数据的波动大小(或称之为波动程度)
- stdvar(): 对样本值求方差 它是求取标准差过程中的中间状态
- min(): 求取样本值中的最小者
- max(): 求取样本值中的最大者
- topk(): 逆序返回分组内的样本值最大的前k个时间序列及其值
- bottomk(): 顺序返回分组内样本值最小的前k个时间序列及其值
- quanlite(): 分位数用于评估数据的分布状态 该函数会返回分组内指定的分位数的值 即数值落在小于等于执行的分位区间的比例
- count_values(): 对分组内的时间序列的样本值进行数量统计
- increase():函数: 求指定时间内的增量
increase 函数
increase函数: 求指定时间内的增量
在prometheus中是用来针对Counter这种持续增长的数值,截取其中的一段时间的增量。
举个例子:
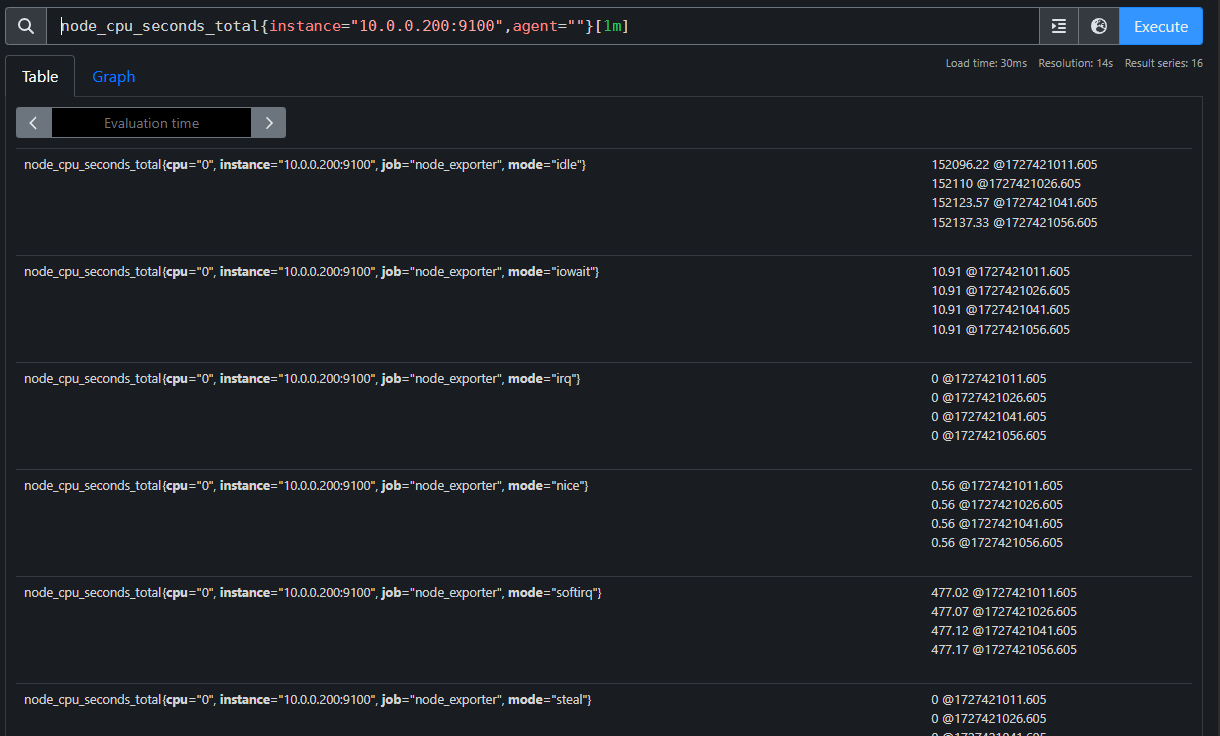
node_cpu_seconds_total{instance="10.0.0.200:9100",agent=""}[1m]
获取CPU总使用时间在1分钟内的增量,计算的是1分钟内增加的总量。
在实际工作中,我们的服务器通常是多核的,因此这个采集的是所有核心的值哟。
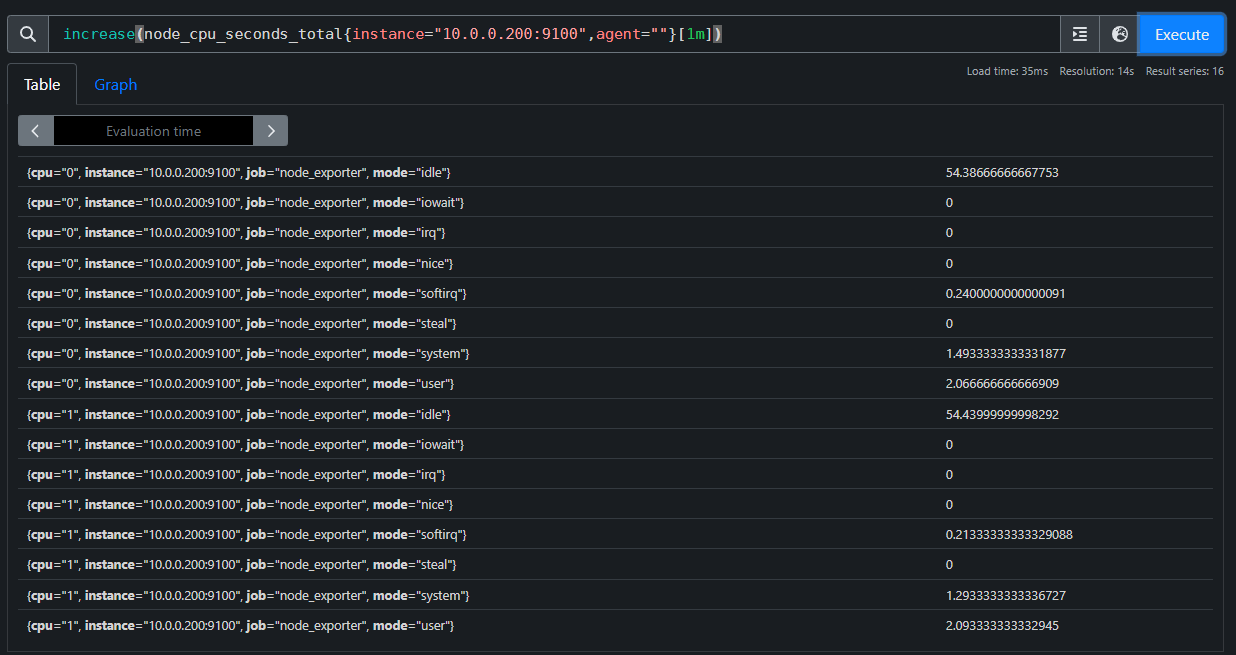
increase(node_cpu_seconds_total{instance="10.0.0.200:9100",agent=""}[1m])
我们也可以借助标签选择器过滤查看某个服务器实例的配置.
sum函数
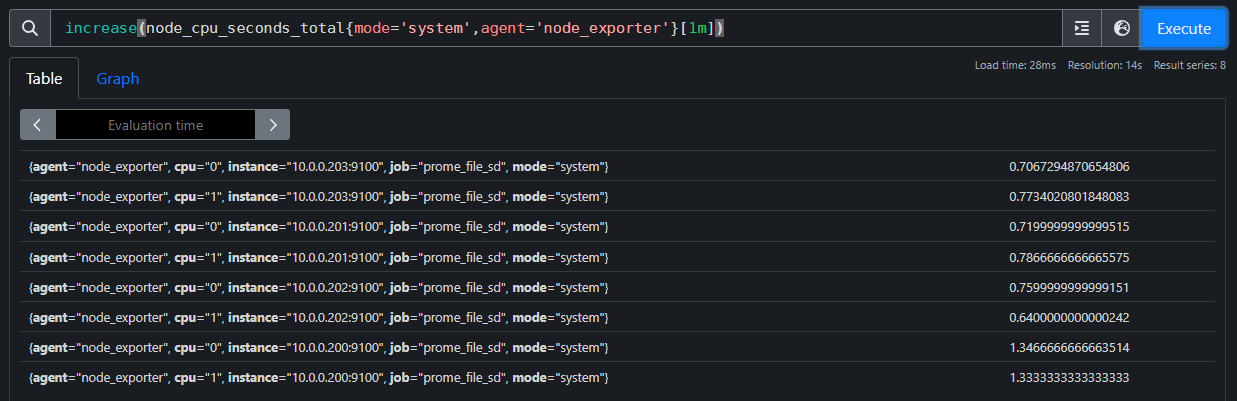
sum(increase(node_cpu_seconds_total{job='prome_file_sd',mode='system'}[1m]))
sum函数:
顾名思义,主要是起到加和的作用。
举个例子:
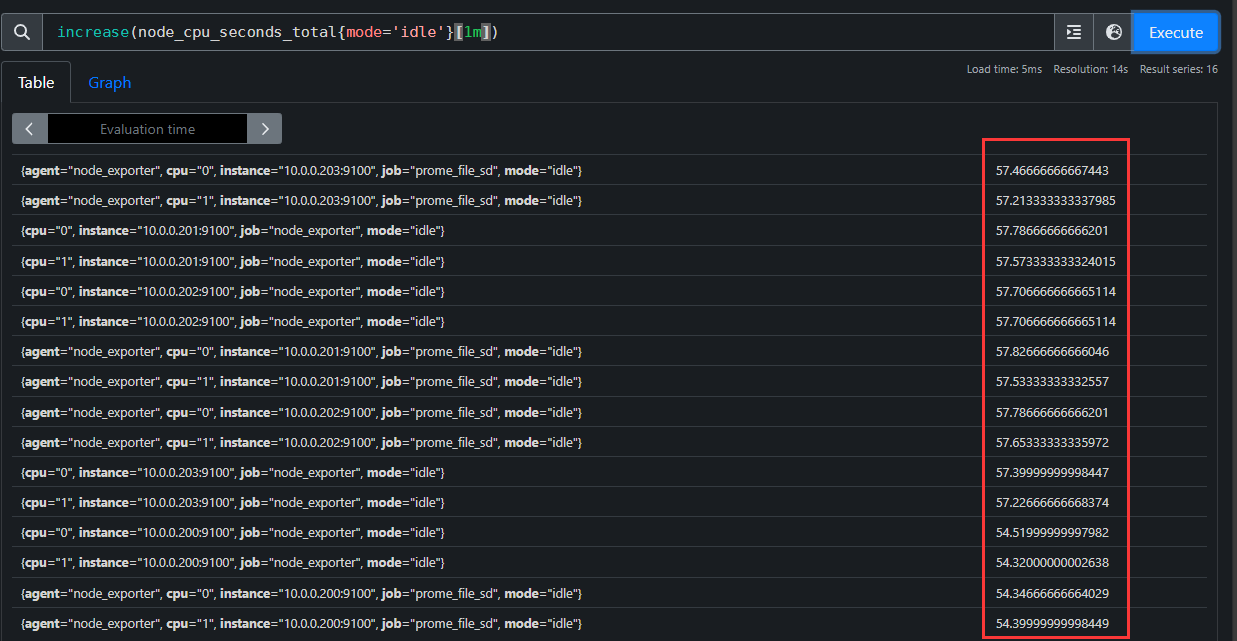
sum(increase(node_cpu_seconds_total[1m]))
sum(increase(node_cpu_seconds_total{job='prome_file_sd',mode='system'}[1m]))
在"increase(node_cpu[1m])"外面套用一个sum函数就可以把所有CPU核心数在1分钟内的增量做一个累加。

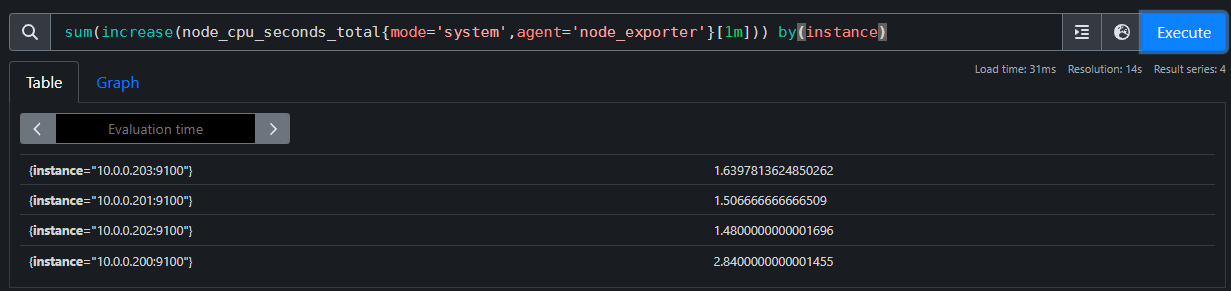
by函数
### 根据主机来进行分组
sum(increase(node_cpu_seconds_total{mode='system',agent='node_exporter'}[1m])) by(instance)
by函数:
将数据进行分组,类似于MySQL的"group by"。
举个例子:
by (instance):
这里的"instance"代表的是机器名称,意思是将数据按照instance标签进行强行拆分。
该函数通常会和sum函数搭配使用,比如"(sum(increase(node_cpu_seconds_total[1m]))
by (instance))",表示把sum函数中累加和按照"instance"(机器名称)强行拆分成多组数据。当然,如果
只有一个机器名称的话,你会发现只有一组数据,因此从结果上可能看不到明显的变化哟。
温馨提示:
instance是node_exporter内置的标签,当然,我们也可以自定义标签,比如根据生产环境中不同的
集群添加相应的标签。比如基于自定义的"cluster_name"标签进行分组等。
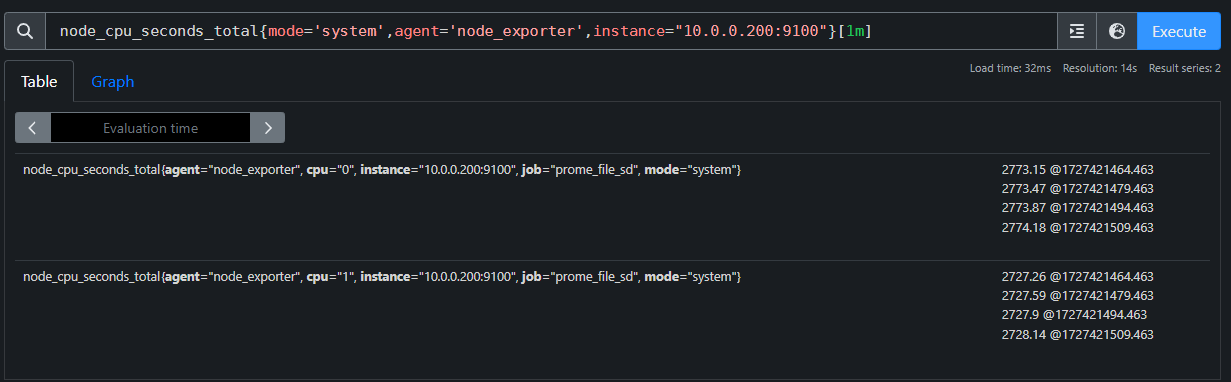
rate函数
rate(node_cpu_seconds_total{mode='system',agent='node_exporter',instance="10.0.0.200:9100"}[1m])
rate函数:
它的功能是按照设置的一个时间段,取counter在这个时间段中的平均每秒的增量。因此是专门搭配
counter类型数据使用的函数。
举个例子:
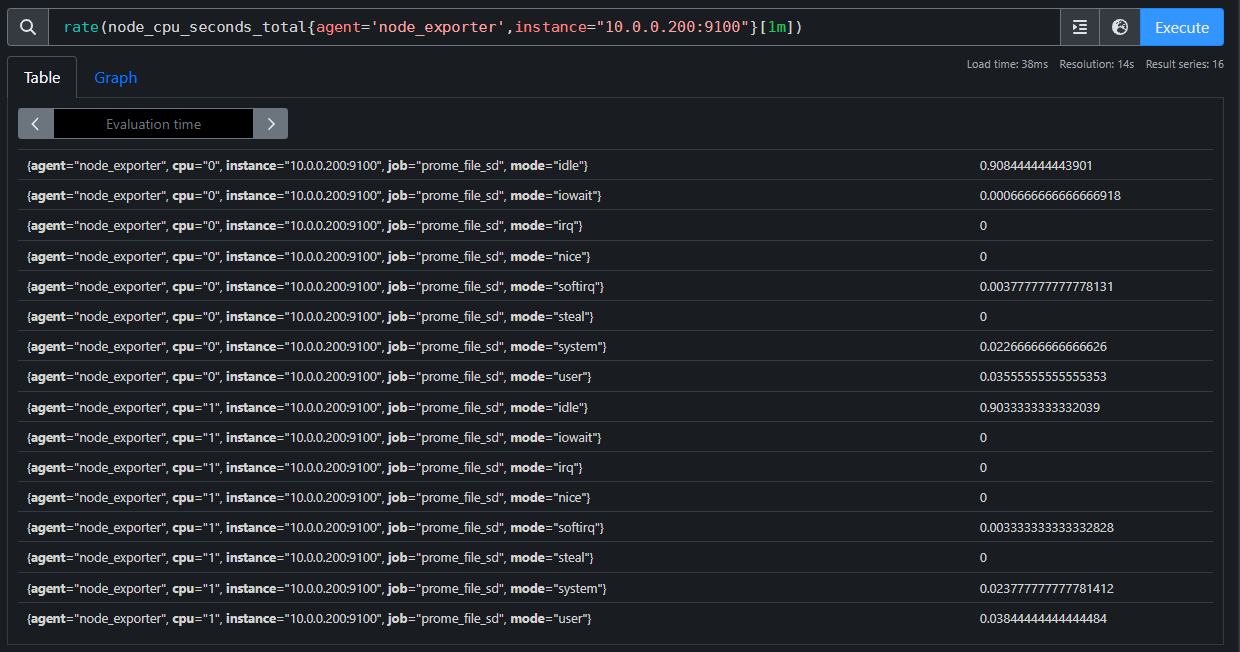
rate(node_cpu_seconds_total[1m]):
获取CPU总使用时间在1分钟内的增加的总量并除以60秒,计算的是每秒的增量。
rate(node_network_receive_bytes_total[1m]):
获取一分钟内网络接收的总量。
查看的时间越短,某一瞬间的突起或降低在成图的时候会体现的更细致,更铭感。
rate(node_network_receive_bytes_total[20m])
获取二十分钟内网络接收的总量。
查看的时间越长,那么当发生瞬间的突起或降低时候,会显得平缓一些,因为取得时间段越长会把
波峰波谷都给平均消下去了。
increase函数和rate函数如此相似如何选择?
(1)对于采集频率较低的数据采用建议使用increase函数,因为使用rate函数可能会出现断点(比如按
照5分钟采样数据量较小的场景,以采集硬盘可用容量为例,可能会出现某次采集数据未采集到的情况,因为会
按照平均每秒来计算最终的增量)的情况;
(2)对于采集频率较高的数据采用建议使用rate函数,比如对CPU,内存,网络流量等都可以基于rate
函数来采样,当然,硬盘也是可以用rate函数来采样的哟;
温馨提示:
在实际工作中,我们取监控频率为1分钟还是5分钟这取决与我们对于监控数据的敏感程度来挑选。

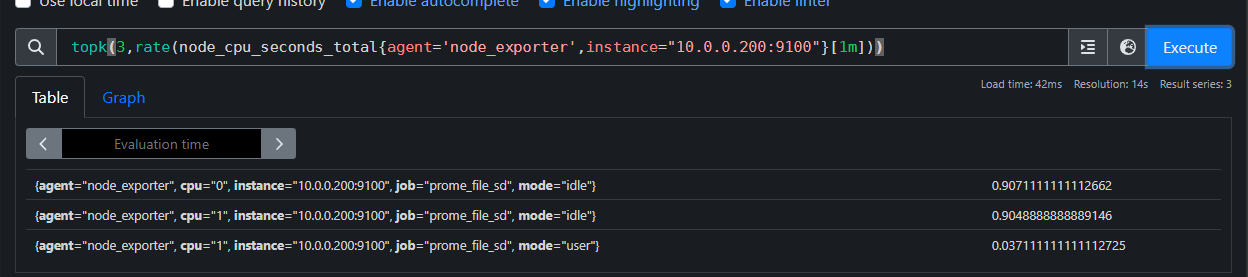
topk函数
topk(3,rate(node_cpu_seconds_total{agent='node_exporter',instance="10.0.0.200:9100"}[1m]))
topk函数:
取前几位的最高值。实际使用的时候一般会用该函数进行瞬时报警,而不是为了观察曲线图。
举个例子:
topk(3,rate(node_cpu_seconds_total[1m])):
获取CPU总使用时间在1分钟内的增加的总量并除以60秒,计算的是每秒的数量。并只查看top3。
count函数
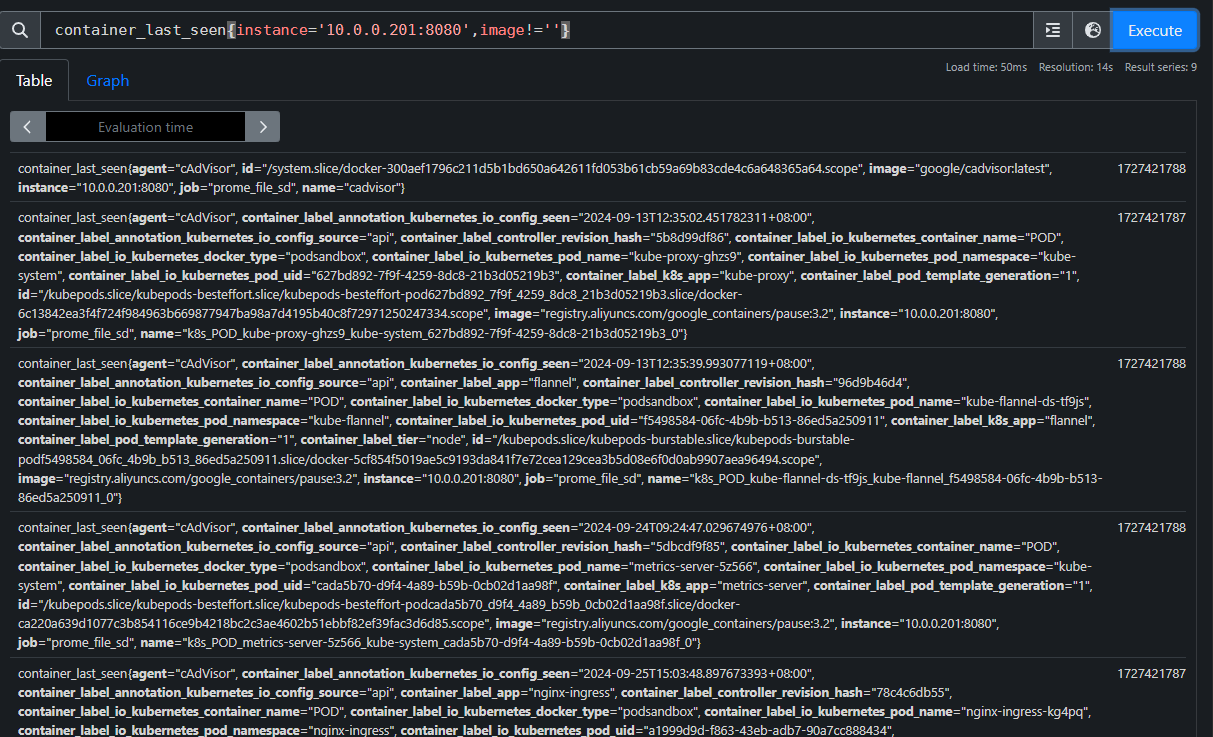
count(container_last_seen{instance='10.0.0.201:8080',image!=''})
统计node01上有多少台容器
count函数:
把数值符合条件的,输出数目进行累计加和。一般用它进行一些模糊的监控判断。
比如说企业中有100台服务器,那么只有10台服务器CPU使用率高于80%的时候,这个时候不需要报警,
当符合80%CPU的服务器数量超过70台的时候那么就触发报警。
举个例子:
count(zls_tcp_wait_conn > 500):
我们假设zls_tcp_wait_conn是咱们自定义的KEY,上述案例是找出当前(或者历史的)当前TCP
等待数大于500的机器数量。

函数练习
# 计算各节点的CPU的总使用率,参考公式: "100% - (CPU空闲时间/总时间)"
## 空闲时间
sum(node_cpu_seconds_total{mode='idle'}) by(instance)
## 总时间
sum(node_cpu_seconds_total) by(instance)
## 每台机器的CPU使用率
1-(sum(node_cpu_seconds_total{mode='idle'})
by(instance)/sum(node_cpu_seconds_total) by(instance))
# 计算用户态的CPU使用率
sum(node_cpu_seconds_total{mode='user'})
by(instance)/sum(node_cpu_seconds_total) by(instance)
# 计算内核态的CPU使用率
sum(node_cpu_seconds_total{mode='system'})
by(instance)/sum(node_cpu_seconds_total) by(instance)
# 计算IO等待的CPU使用率
sum(node_cpu_seconds_total{mode='iowait'})
by(instance)/sum(node_cpu_seconds_total) by(instance)