Alertmanager告警
配置alertmanager
[root@master01 ~]# vim /app/alertmanager/alertmanager.yml
global:
resolve_timeout: 5m # 指定报警解决的超时时间
smtp_from: '[email protected]' # 发件人邮箱地址
smtp_smarthost: 'smtp.qq.com:465' # SMTP 服务器地址及端口
smtp_auth_username: '[email protected]' # SMTP 认证用户名
smtp_auth_password: 'xxxxxxxxxxxxxxx' # SMTP 认证密码
smtp_require_tls: false # 是否要求使用 TLS 连接
smtp_hello: 'qq.com' # SMTP HELO 参数
route:
group_by: ['alertname'] # 按照 alertname 分组
group_wait: 5s # 分组等待时间
group_interval: 5s # 分组之间的间隔时间
repeat_interval: 5m # 重复发送报警的时间间隔
receiver: 'email' # 默认接收者
receivers:
- name: 'email' # 接收者的名称
email_configs:
- to: '[email protected]' # 发送到的邮箱地址
send_resolved: true # 是否发送已解决的通知
inhibit_rules:
- source_match:
severity: 'critical' # 源报警的严重性级别
target_match:
severity: 'warning' # 目标报警的严重性级别
equal: ['alertname', 'dev', 'instance'] # 需要匹配的字段
[root@master ~]# vim /app/alertmanager/alertmanager.yml
global:
resolve_timeout: 5m
smtp_from: '[email protected]'
smtp_smarthost: 'smtp.qq.com:465'
smtp_auth_username: '[email protected]'
smtp_auth_password: 'qxiynwxxxxxxx'
smtp_require_tls: false
smtp_hello: 'qq.com'
route:
group_by: ['alertname']
group_wait: 5s
group_interval: 5s
repeat_interval: 5m
receiver: 'email'
receivers:
- name: 'email'
email_configs:
- to: '[email protected]'
send_resolved: true
inhibit_rules:
- source_match:
severity: 'critical'
target_match:
severity: 'warning'
equal: ['alertname', 'dev', 'instance']
配置prometheus关联alertmanager
[root@master01 ~]# vim /app/prometheus/prometheus.yml
# Alertmanager configuration
alerting:
alertmanagers:
- static_configs:
- targets:
- 10.0.0.200:9093
[root@master01 ~]# supervisorctl restart prometheus
配置触发器
groups: # 定义报警组的开始
- name: user-count # 组的名称,用于标识这一组报警
rules: # 开始定义报警规则
- alert: user-count # 报警的名称,用于引用和识别
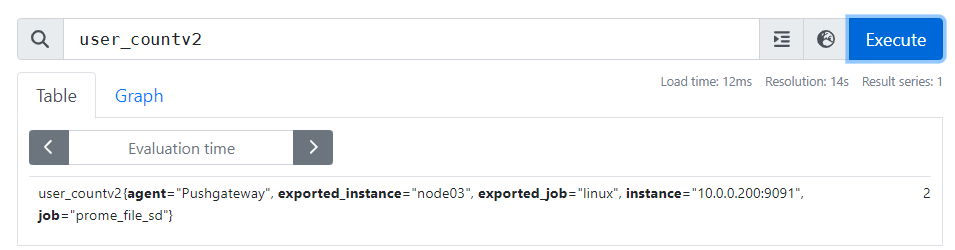
expr: user_countv2 > 3 # 触发报警的表达式,当用户数量大于 3 时触发
for: 15s # 需要满足条件的持续时间,必须持续 15 秒才会触发报警
labels: # 为报警添加标签,方便分类和筛选
severity: "1" # 报警的严重性级别(可以是字符串或数字,通常用于排序和处理)
team: "node" # 负责处理该报警的团队
level: "application" # 报警的层级标签,指示这是应用级别的报警
component: "login-service" # 指定报警来源的组件,帮助识别问题的具体服务
environment: "production" # 指定报警的环境,如生产环境或开发环境
annotations: # 提供额外信息,通常用于报警通知中
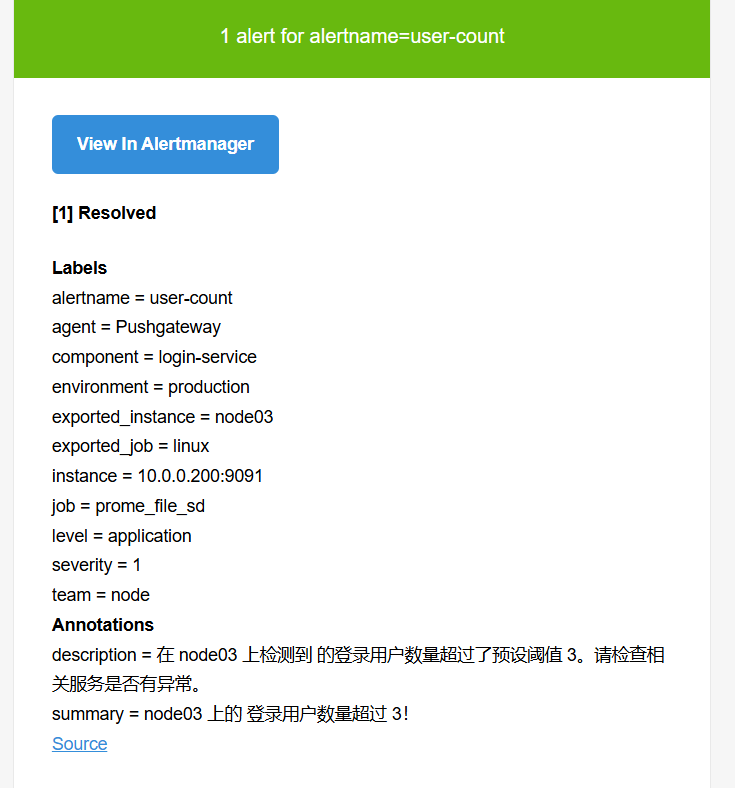
summary: "{{ $labels.exported_instance }} 上的 {{ $labels.component }} 登录用户数量超过 3!" # 报警摘要,提供简洁的信息
description: "在 {{ $labels.exported_instance }} 上检测到 {{ $labels.component }} 的登录用户数量超过了预设阈值 3。请检查相关服务是否有异常。" # 报警详细描述,提供更多上下文,指导后续处理
## 配置触发器规则存放目录
[root@master01 ~]# vim /app/prometheus/prometheus.yml
# Load rules once and periodically evaluate them according to the global
'evaluation_interval'.
rule_files:
- "/app/prometheus/alertmanager/user_count.yml"
# - "second_rules.yml"
vim /app/prometheus/alertmanager/user_count.yml
groups:
- name: user-count
rules:
- alert: user-count
expr: user_countv2 > 3
for: 15s
labels:
severity: "1"
team: "node"
# 假设添加一些层级标签
level: "application"
component: "login-service"
# 如果需要,还可以添加环境或其他标识
environment: "production"
annotations:
summary: "{{ $labels.exported_instance }} 上的 {{ $labels.component }} 登录用户数量超过 3!"
description: "在 {{ $labels.exported_instance }} 上检测到 {{ $labels.component }} 的登录用户数量超过了预设阈值 3。请检查相关服务是否有异常。"
#### 加入supervisorctl 管理
[program:prometheus]
directory=/app/prometheus/
command=/bin/bash -c "/app/alertmanager/alertmanager --config.file=/app/alertmanager/alertmanager.yml"
autostart=true
autorestart=true
stdout_logfile=/var/log/prome_stdout.log
stderr_logfile=/var/log/prome_stderr.log
user=root
stopsignal=TERM
startsecs=5
startretries=3
stopasgroup=true
killasgroup=true
[root@master alertmanager]# supervisorctl update
[root@master alertmanager]# supervisorctl restart all
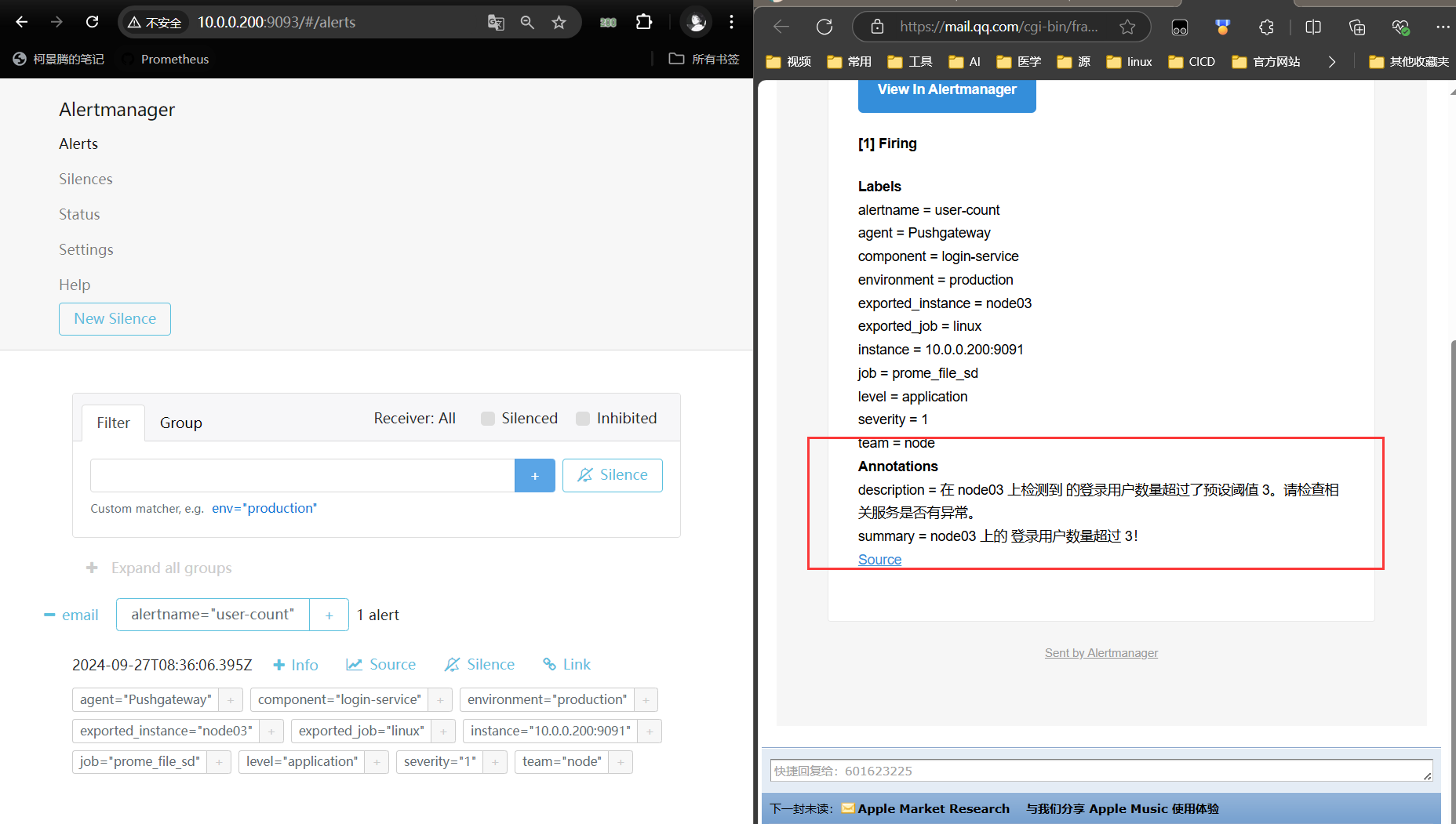
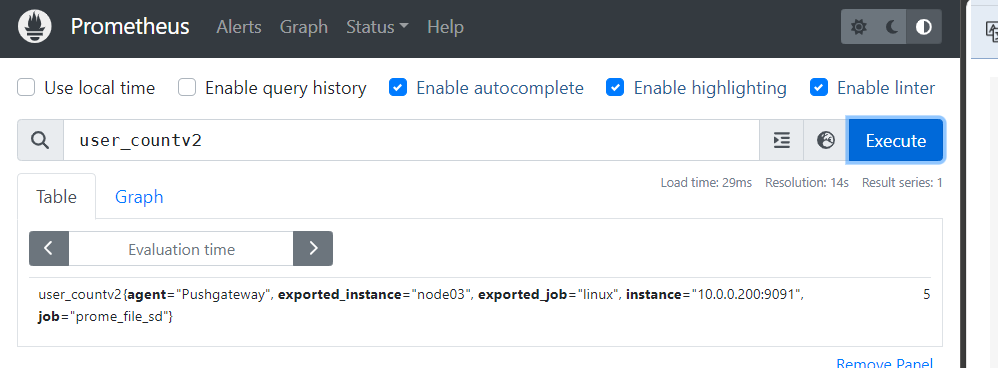
恢复后也发邮件