MySQL索引执行计划
索引介绍
1)索引就好比一本书的目录,它能让你更快的找到自己想要的内容。
2)让获取的数据更有目的性,从而提高数据库检索数据的性能。
索引算法
Btree算法:B树索引(默认)
HASH算法:HASH索引
FULLTEXT:全文索引
RTREE:R树索引
使用什么算法的索引,和MySQL的存储引擎有关(innodb)
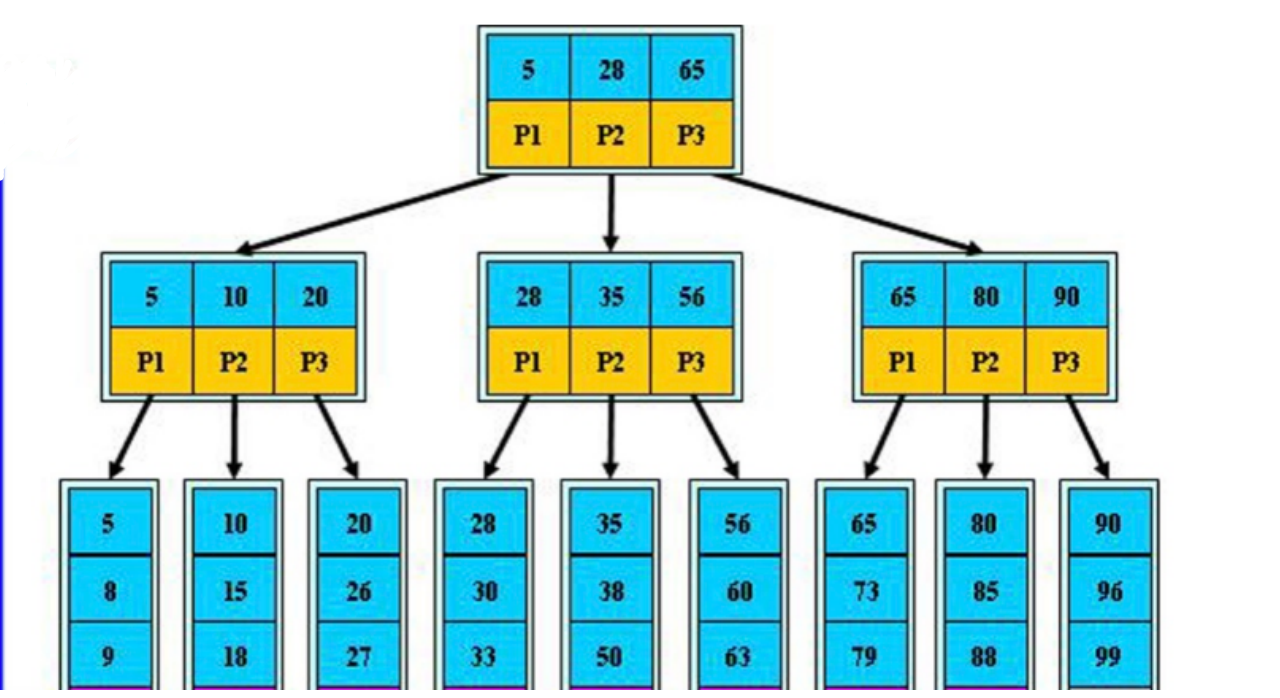
Btree算法介绍
# 规律: 三路Btree
1.每个页上只有三个数据
2.每一页上的值都是下一路数据上的最小值
## 根节点
## 枝节点
## 叶子节点
# 精确查询
select * from tb1 where id=32; 3次IO
# 范围查询
select * from tb1 where id>25 and id <36; 9次IO
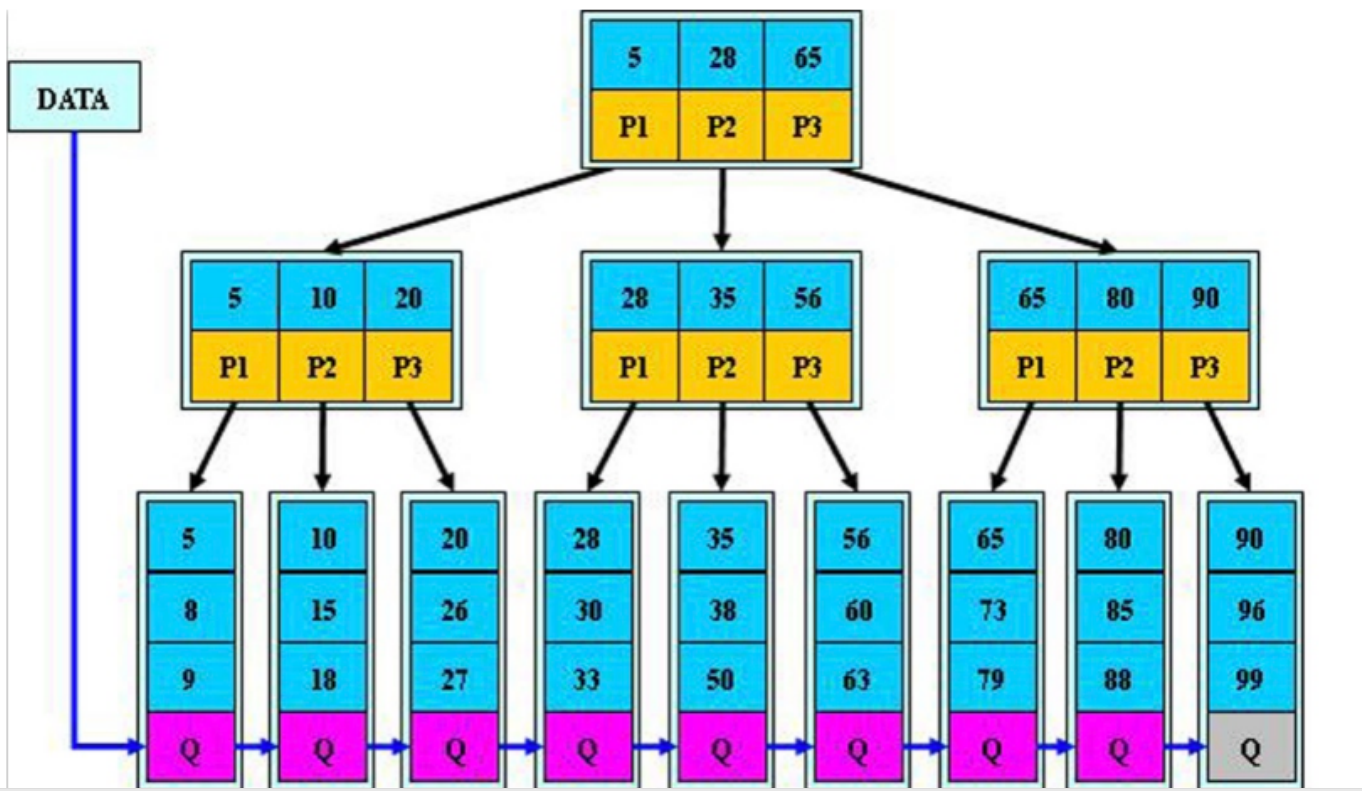
B+tree算法介绍
# 规律: 三路Btree
1.每个页上只有三个数据
2.每一页上的值都是下一路数据上的最小值
## 根节点
## 枝节点
## 叶子节点
# 精确查询
select * from tb1 where id=32; 3次IO
# 范围查询
select * from tb1 where id>25 and id <36; 5次IO
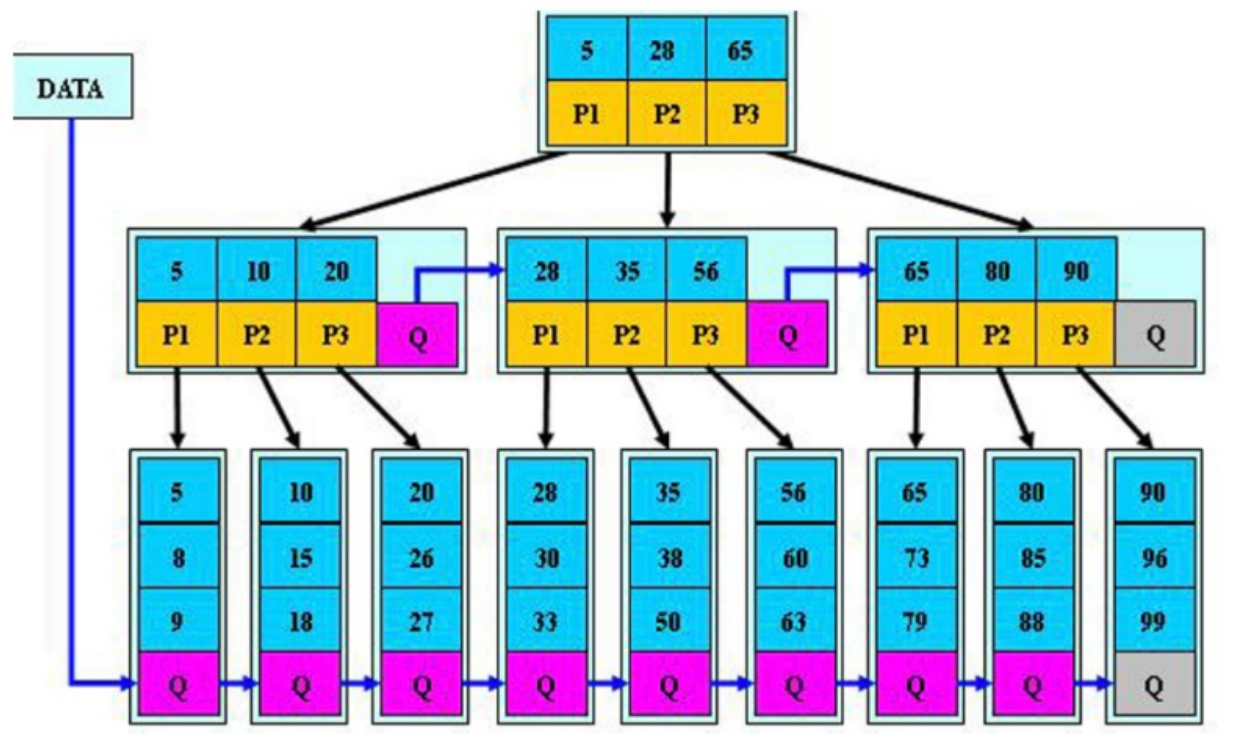
### Btree算法和B+tree算法的区别
1.B+tree算法,优化了范围查询
2.在相邻的叶子节点上添加了指针
B*tree算法介绍
索引分类
# 主键索引(聚簇索引)
- 联合索引
# 唯一索引
- 联合索引
- 前缀索引
# 普通索引
- 联合索引
- 前缀索引
## 查看索引
root@localhost:(none) 09:12:11> desc mysql.user;
root@localhost:(none) 09:12:19> show create table mysql.user;
root@localhost:(none) 09:13:26> show index from mysql.user;
注意:索引不是越多越好,避免给大列创建索引
1.索引会进行排序,大列创建索引速度慢
2.索引越多占用磁盘空间越大
索引的创建规则
为了使索引的使用效率更高,在创建索引时,必须考虑在哪些字段上创建索引和创建什么类型的索引。
每张表必须有一个主键索引
1.能创建唯一索引就创建唯一索引
select count(population) from world.city;
select count(distinct(population)) from world.city;
2.如果重复值比较多的情况下,联合索引
3.为经常需要排序、分组和联合操作的字段建立索引
4.为常作为查询条件的字段建立索引
5.尽量使用前缀来索引
# 限制索引的数目
1 索引的数目不是越多越好。每个索引都需要占用磁盘空间,索引越多,需要的磁盘空间就越大。
2 修改表时,对索引的重构和更新很麻烦。越多的索引,会使更新表变得很浪费时间。
# 删除不再使用或者很少使用的索引
1 表中的数据被大量更新,或者数据的使用方式被改变后,原有的一些索引可能不再需要。数据库管理
2 员应当定期找出这些索引,将它们删除,从而减少索引对更新操作的影响。
索引的操作
############## 普通索引 ################
#-- 添加索引
alter table 表名 add index 索引名(字段);
alter table stu2 add index idx_name(name);
#-- 删除索引
alter table 表明 drop index 索引名;
alter table stu2 drop index idx_name;
############# 唯一键索引 ###########
#---判断字段中是否存在重复的值
select count(population) from world.city; ## 统计行数
select count(distinct(population)) from world.city; ## 去重 比较行数 相同则唯一键
#---- 添加唯一键索引
alter table 表名 add unique key 索引名(字段)
alter table stu30 add unique key uni_phone(phone);
#--- 删除唯一键索引
alter table 表名 drop index 索引名;
alter teble stu30 drop index uni_phone;
############# 主键索引 ###############
## -----创建表添加主键索引
create table stu1(id int primary key auto_increment,name varchar(10));
## ---- 添加主键索引
alter table 表名 add primary key(字段);
alter table stu2 add primary key(id);
## --- 删除主键索引 PS: 主键存在数据无法删除
alter table 表名 drop primary key
alter table stu2 drop primary key;
前缀索引
解决给大列创建索引排序速度慢的问题
## 普通索引创建前缀索引
alter table 表名 add indenx 前缀索引名(字段(前缀数));
alter table stu30 add index idx_phone(phone(3));
## 唯一索引创建前缀索引
alter table stu30 add unique key uni_phone(phone(3));
## 删除索引
alter table 表名 drop 前缀索引名;
联合索引
一张表中,哪些字段需要创建索引,取决于用户需求
当一张表中,需要创建索引的字段比较多的时候
## -- 创建普通的联合索引
alter table 表名 add 索引名(字段A,字段B,字段C);
alter table xiangqin add indexidx_all(gender,salary,body);
## -- 创建唯一键的联合索引
alter table 表名 add unique key 索引名(字段A,字段B,字段C);
alter table xiangqin add unique key uni_all(gender,salary,body);
## -- 删除索引
alter table 表名 drop 索引名;
MySQL数据扫描
####### 全表扫描 ##########
1. select * from 表;
2. select 查询数据时,where条件接的字段没有创建索引 (不走索引)
###### 索引扫描 #########
1. index # 全索引扫描 countrycode 是一个索引
explain select countrycode from world.city;
2.range # 范围查询并且创建了索引 population是一个索引 如果超过了25%就会全局扫描
explain select * from world.city where population > 1000 limit 5;
3.ref ## 联合查询, 普通索引的精确查询
select * from world.city where countrycode='CHN' or countrycode='USA'; ## range类型
select * from world.city where countrycode in ('CHN','USA'); ## range类型
select * from world.city
where countrycode='CHN'
union all
select * from world.city
where countrycode='USA'; ### ref 类型
4.eq_ref ## 连表查询使用 join on 小表在前 大表在后
explain select country.name as 国家名,city.name as 城市名,city.population as 城市人口数量
from city,country
where city.countrycode=country.code and city.population<100;
5.const ,system ## 主键精确查询
explain select * from city where id = 20 ;
6.null ## 查询不到 或者不在索引范围
key_len: 越小越好 , 前缀索引去控制
rows: 越小越好